Word2Vec
词的表示方式
首先最传统的是 ont-hot 表示,但是 one-hot 有很明显的缺点:
- 词越多,维数越高
- 无法表示词与词之间的关系
语言模型
语言模型是计算一个句子是句子的概率的模型。
例如:
- 今天的天气真好
- 天气的今天真好
上面两个句子中,很明显第一个是句子的概率更高,它合乎语义,也合乎语法。当我们在输入法中输入拼音时,会返回多条语句,这时候就需要语言模型帮助我们选择概率最高的语句。
基于专家语法规则的语言模型
语言学家企图总结出一套通用的语法规则,比如形容词后接名词。但是这种方式有很明显的缺点:
- 语言千变万化,很难总结。
- 语言随着时代变化会不断变化,例如一些网络用语。
统计语言模型
也就是通过概率来刻画语言模型
用语料的频率代替概率,即
其中
进而,有
但是上面这种方式有两个问题:
- 如果有一些生僻词,例如一个人起名为"张很帅",句子为"张很帅很帅"。即使句子合乎语法和语义,但是由于"张很帅"没有从语料库中出现过,因此是句子的概率很小。
- 如果句子太长,例如"张三的妹妹的表哥的侄子的姐姐很漂亮",也会导致最后的概率很小。
因此就有了统计语言模型的平滑操作。例如,拉普拉斯平滑,即每个词在原来出现次数的基础上+1。即
但是这种平滑针对的是词,而不是词组。例如,假如训练语句只有一句话:"张三很美",则句子"张三很帅"和"张三很桌子"的概率是一样的。
另外,此时仍有两个问题没有解决:
- 参数空间过大。每个单词的概率数量有 V 个,则两个单词就有
个,n 个单词组成的词组就有 个。 - 数据稀疏严重。
这就要引出马尔可夫假设:下一个词的出现仅仅依赖于前面的一个词或者几个词。
语言模型的评价指标
一般用困惑度 (Perplexity)来评价语言模型。
句子概率越大,语言模型越好,困惑度越小。其实困惑度也是符合直觉的,要想困惑度越小,就需要
但在实际训练中,我们往往使用 Loss 来计算困惑度。
Word2Vec
语言模型的基本思想:用前面的词预测下一个词。而 Word2Vec 可以看作是对语言模型的简化,即通过相近的词预测词。
Skip-gram 模型

如图,假如输入的中心词是
CBOW 模型
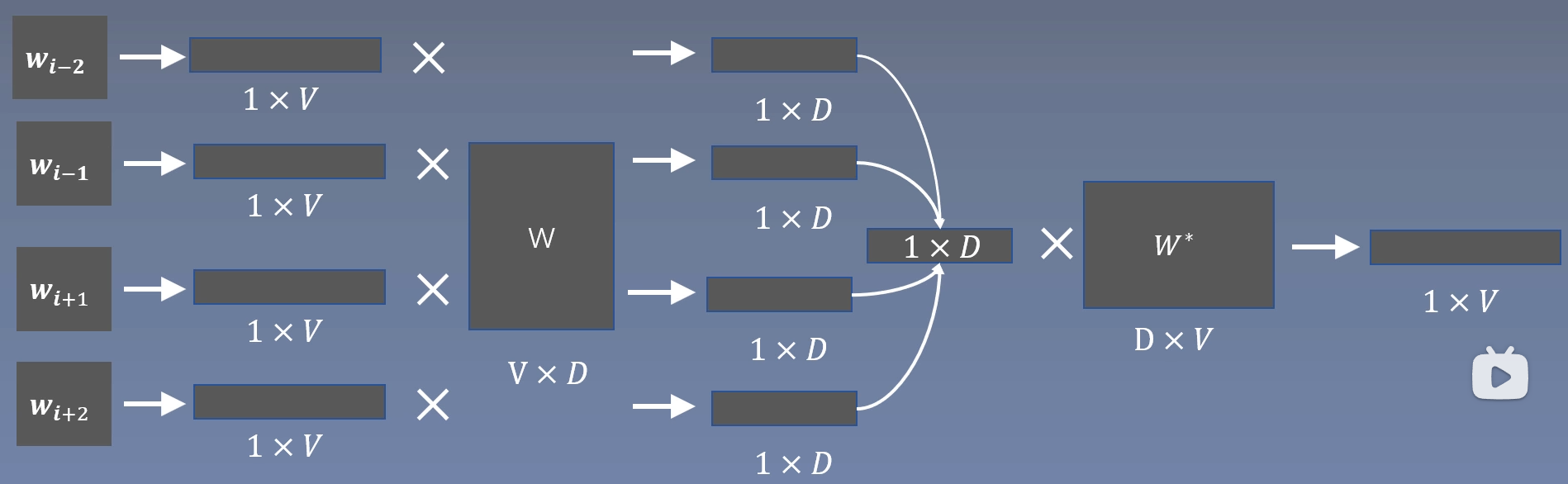
与 skip-gram 模型不同,CBOW 中一组中心词和周围词只能生成一个训练样本。
Word2Vec
https://d4wnnn.github.io/2024/04/16/AI/Word2Vec/