EAGLE-1 解读
Paper:EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Publish:ICML 2024,Arxiv 2024.1.26
在 LLM 推理加速领域,有一类常见的方法是 Speculative Decoding,也就是投机解码。大致思想就是先用小模型一次性预测一些 Token,然后大模型再去并行验证,进而提升推理速度。在 Token-Level 的预测有一个问题,就是准确率低下。
EAGEL 的想法是,既然在 Token Level 预测效果一般,为什么不换到 Feature Level 呢?
加速流程细节
假设大模型输入的是 “How can”, 这个时候需要生成后面的 Token。
在 LLM 的倒数第二层(Transformer Block),经过 KQV 矩阵运算,得到了 “can” 位置的特征向量
- 特征向量
进入大模型的全连接层,采样得到下一个真实的词 。 和 一起被送入Draft Model。
然后 Draft Model 将
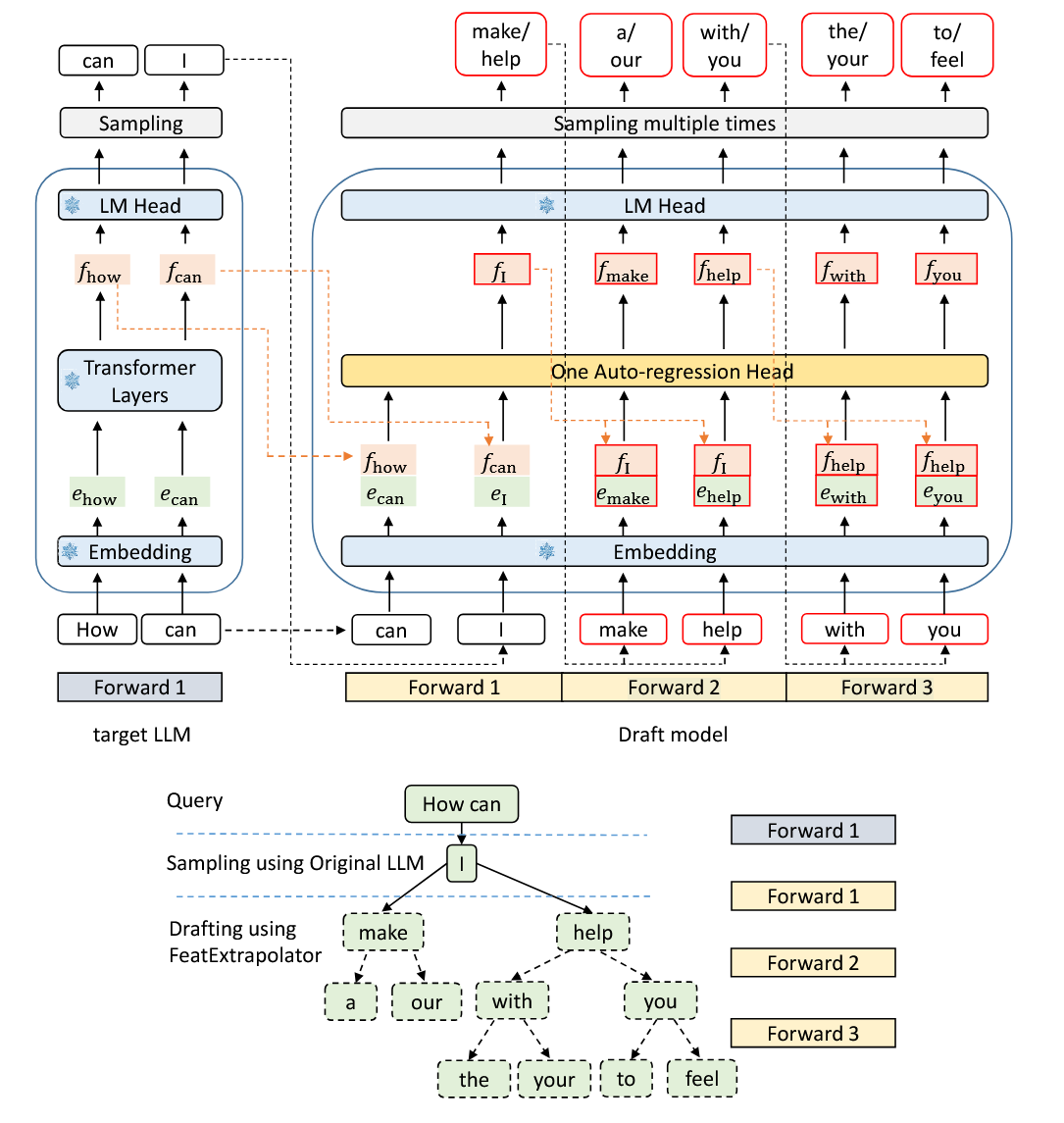
Draft Model 在每一步采样时,会采样多个,因此最后会形成一个 Token Tree. 然后主模型把这个Token Tree 输入,跑一次完整的前向传播,能够计算所有草稿词的概率。
如何训练?
使用现有高质量对话数据集 ShareGPT,输入模型,记录倒数第二层的特征向量
- 回归损失:
,让小模型的输出向量逼近真实向量 - 分类损失:
,确保预测的特征向量经过 LM Head 映射后,得到的 Token 也是正确的。
实验结果如何?
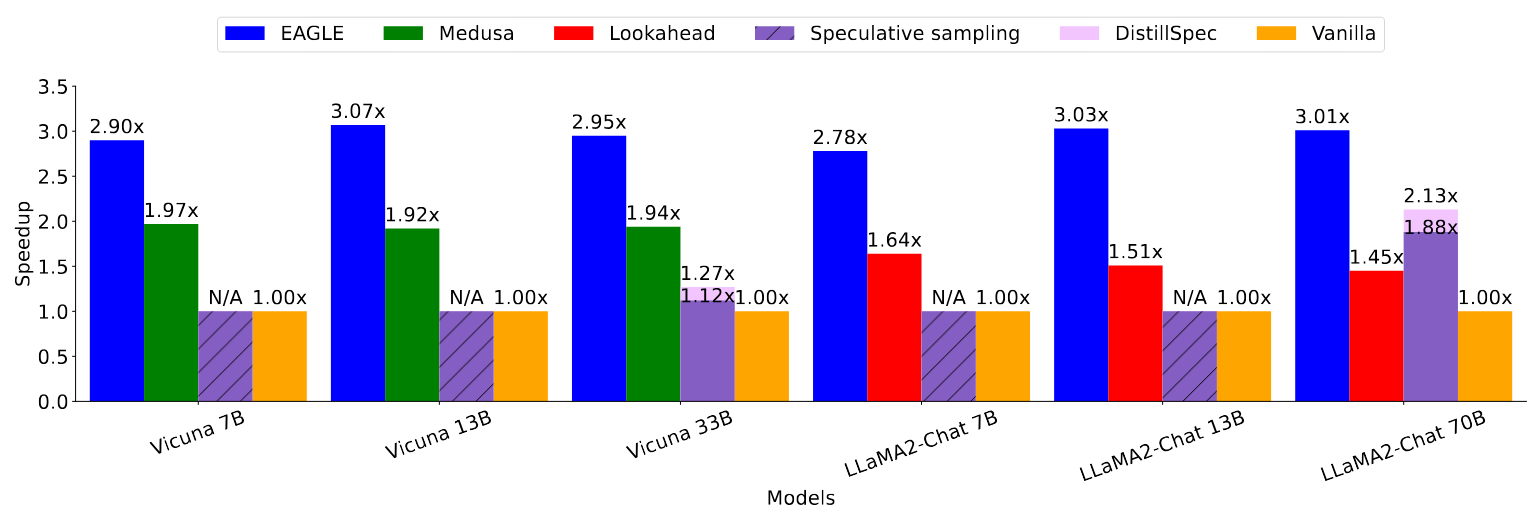
值得注意的是,7B 模型已经很小,需要一个更小的模型来充当 Draft Model,但是很难找到,所以标记为 N/A。