EAGLE-2 解读
Paper:EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
Publish:EMNLP 2024,Arxiv 2024.6.24
EAGLE-2 是在 EAGLE-1 的基础上进行了改进。在前文的 EAGLE-1 上,我们提到了一个 Token Tree 的概念,也就是说,Draft Model 在预测时会生成一系列可能的分支,但是这个 Token Tree 是静态的,无论什么场景,最后都要统一送入 LLM 进行验证。
但是观测如下的场景,当模型输入 “10+2” 时,下一个 Token 可能是 “+” 也可能是 “=”,这个时候没有问题。但是如果模型的输入变成 “10+2=” 时,下一个 Token 几乎一定就是 “1”,这个时候其余的分支就没有意义,所以在这里还有优化的空间。
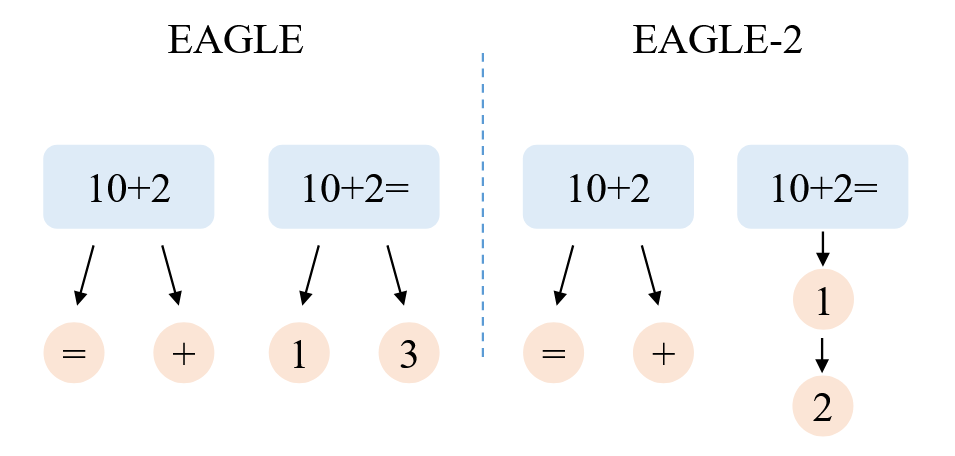
因此 EAGLE-2 的核心创新点是提出了一个上下文感知的动态 Draft Token Tree,可以实时调整树的形状。
如何优化?
作者发现 Draft Model 输出的置信度和原始大模型的接受率是存在强相关的,因此我们可以直接用 Draft Model 的概率值来预测这个 Token 是否有可能被验证通过。
因此事情就变得简单起来,设
每层只挑出
可视化如下:
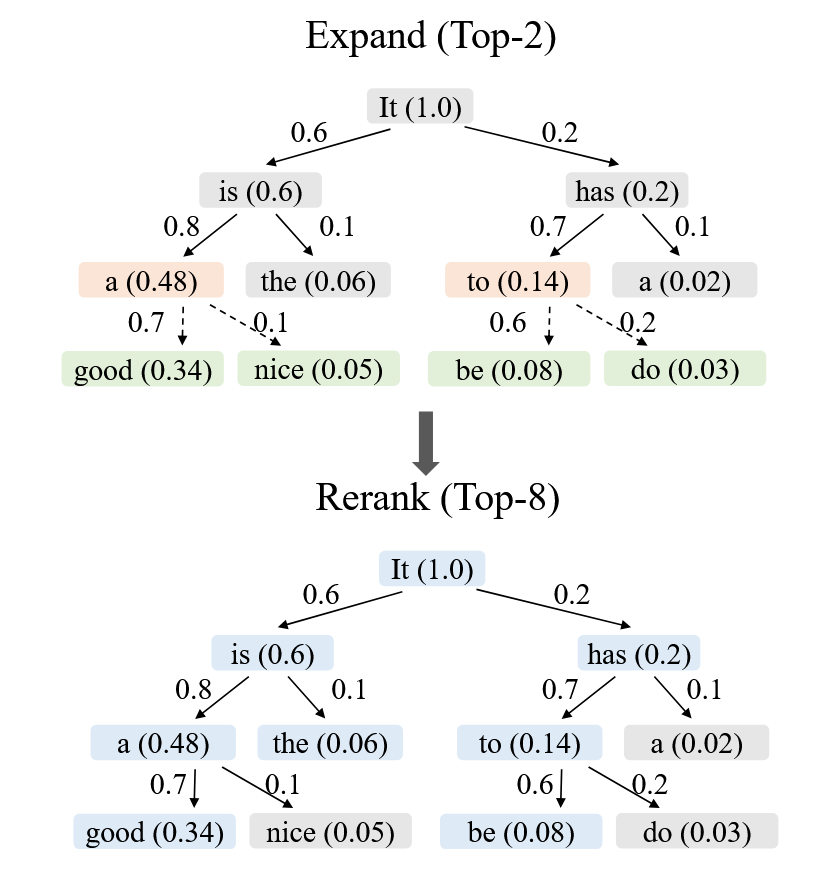
然后得到如下的 Token 序列进行验证:

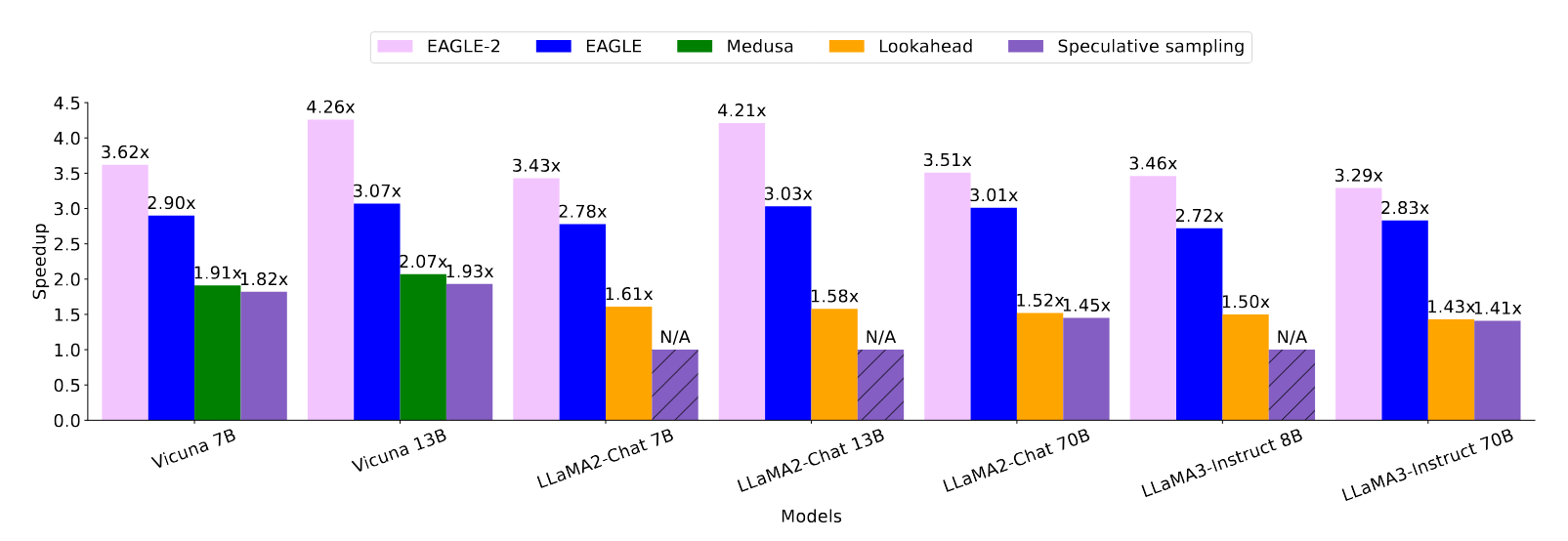
实验结果如何?
EAGLE-2 解读
https://d4wnnn.github.io/2026/03/10/Notion/EAGLE-2 解读/