EALGE-3 解读
Paper:EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Publish:NeurIPS 2025,Arxiv 2025.3
EAGLE 作者发现一个很奇怪的现象,就是仅仅增加 Draft Model 的训练数据,并不能持续提升加速比。论文总结了两点原因:
- 输入信息受限。Draft Model 的输入只有倒数第二层。
- 特征预测的约束。之前的 Draft Model 的训练,有一个 Loss 函数是拟合原始 LLM 的特征向量,这样就会限制表达能力。
因此论文 EAGLE-3 来解决上述问题。
如何加速?
首先第一步是增加输入信息,EAGLE-3 将模型的底层、中层、高层特征进行拼接,再通过 MLP 融合:
第二步是改变 Loss 函数。只保留预测 Token 的损失函数。另外在训练时不再使用 LLM 的真实特征,而是将 Draft Model 自己的预测向量反馈给模型。
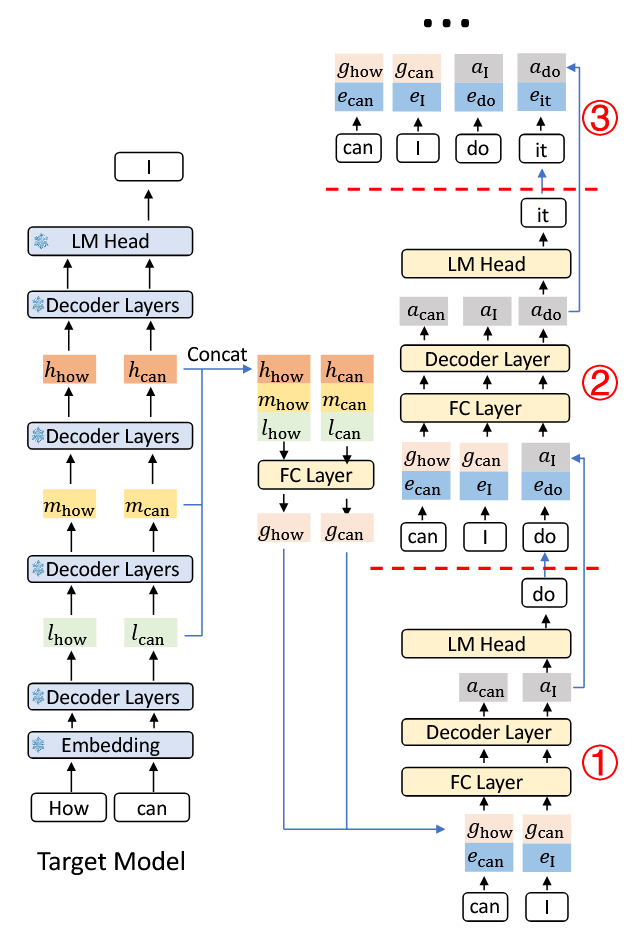
具体的 Pipline 如上,EAGLE-3 与前作相比,主要改变方式在训练阶段。EAGLE-3 去除了特征约束,如果只去除特征约束,效果雪崩,因此也要改变训练范式。EAGLE-1 和 EALGE-2 的训练阶段的输入的隐藏向量是 LLM 的真实输出,但是现在改变成了 Draft Model 自己的输出。
结果如何?
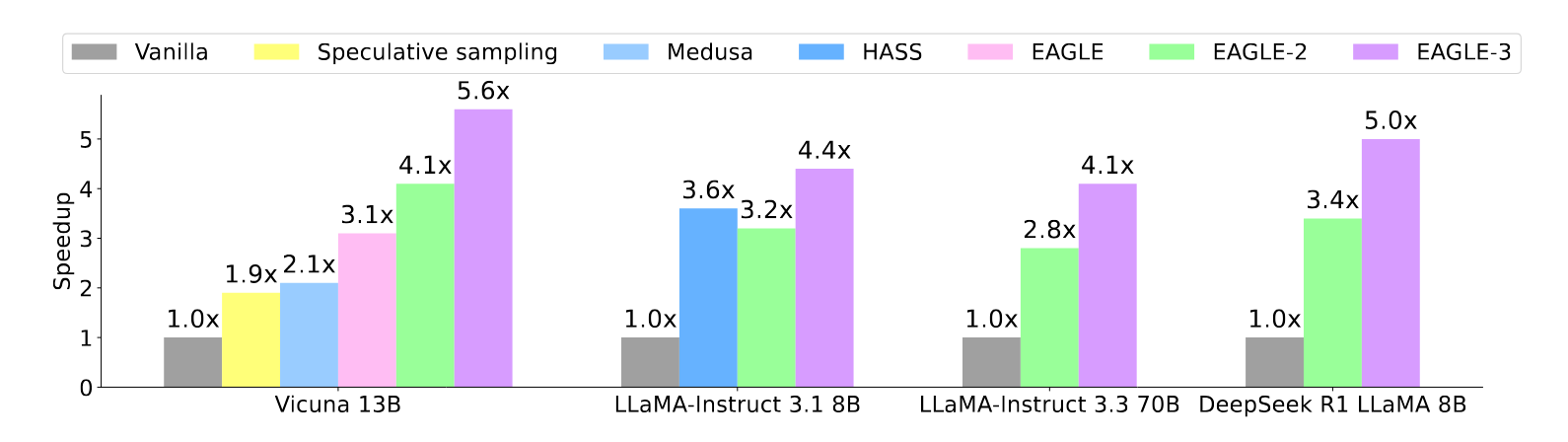
EALGE-3 解读
https://d4wnnn.github.io/2026/03/10/Notion/EALGE-3 解读/