LLM4Traffic
Paper:LLM4Traffic: Adapting the Large Language Models to Secure and Efficient Network Traffic Fingerprinting
其实在加密流量分析领域,我一直想做一些结合 LLM 的方向,但是一直不知如何下手,LLM4Traffic 给了我一些启发。
LLM4Traffic 这篇论文提出基于预训练或者 LLM 的流量分析存在如下痛点,其实也很符合直觉:
- 学习效率低:机械的将流量编码为字节序列。
- 不够鲁棒:过细的流量编码导致模型容易进行 shortcut-learning。
- 缺乏交互信息建模:LLM 更加擅长处理序列,但是不擅长处理复杂的交互关系,比如请求相应。
论文是如何解决痛点的?
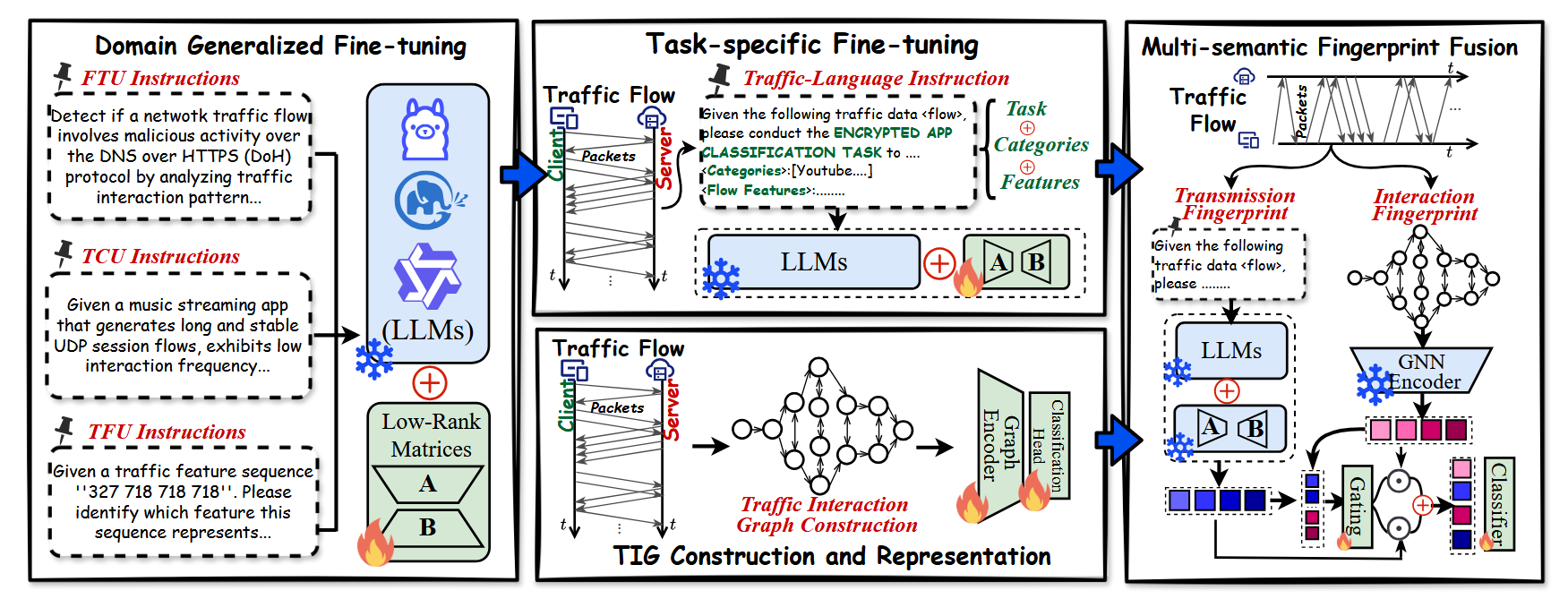
论文的微调分为两个阶段,首先是领域泛化微调,也就是让模型了解网络流量的通用背景知识。第二步是任务特定微调,也就是在特定数据集上进行二次微调。
那么领域泛化微调是怎么进行的呢?
- FTU:Fingerprinting Tasks Understanding,任务理解。描述一种攻击,比如通过向目标发送持续的、周期的请求来耗尽带宽,问模型是什么任务,让模型回答 DDoS。
- TCU:Traffic Categories Understanding,类别理解。提供 254 种不同类别流量的经验性描述,比如一种流行的在线音乐流媒体,UDP 绘画稳定,交互频率低,让模型回答是什么类别,回答 Spotify。
- TFU:Traffic Features Understanding,特征理解。提供真实的流量特征序列作为问题,比如序列“327,718,718”代表什么特征?模型回答报文长度序列。
在经过领域泛化微调后,模型就强化了基本的流量分类的背景知识。接下来进行任务特定微调。其实也就是 Prompt 如何组织的问题,分成三部分:
- 任务描述:比如请进行流量分类的任务,确定流量所属类别。
- 类别候选:比如备选类别是xxx。
- 流量特征:长度序列,方向序列,时间间隔序列。
作者认为,LLM 并不适合处理流量这种结构性很强的数据,于是引入交互信息作为补充。具体如下:
将 Packet 视作节点,然后分成三种边:
- 同一个 Burst 内,时间相邻。
- 请求响应边,也就是相邻但是方向相反。
- 相邻两个同向的 Burst。
利用门控机制,将 LLM 的输出和 GNN进行融合。注意论文取的是输出的所有 Token 的平均值作为指纹。
消融实验如何?
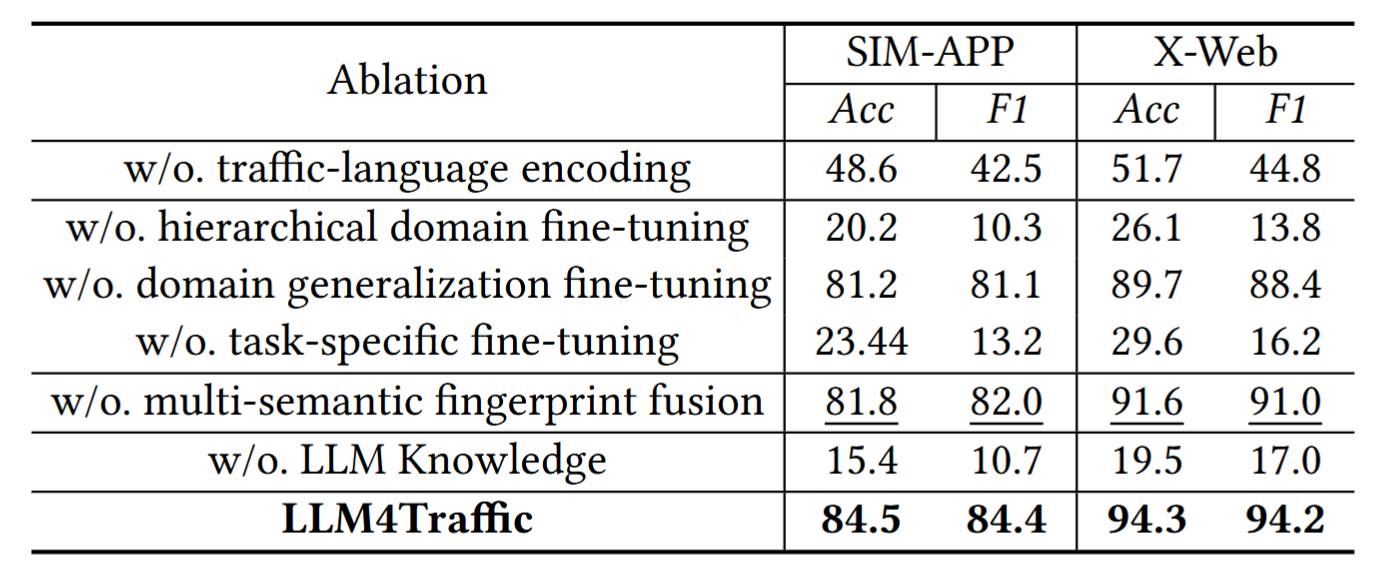
消融实验如上。总结如下:
- 如果没有任务特定的微调,效果很差,Acc 只剩下 23.44%,因此其实 LLM 的泛化能力一般。
- 去掉 GNN 只掉了 3 个点,因此这个意义不大。
- 如果将 Prompt 改成字节序列,效果就很差,指标下降到 48.6%。
- 去掉领域泛化微调,掉下了2个点。
因此不难看出,最关键的还是在特定数据集上进行微调,另外不能输入原始字节。
LLM4Traffic
https://d4wnnn.github.io/2026/03/13/Notion/LLM4Traffic/