U-Net 的细节理解
Paper:U-Net: Convolutional Networks for Biomedical Image Segmentation
印象里只知道 U-Net 是分割领域的一个模型而已,后面在很多其他地方看到越来越多它的影子,但是很多地方一直有些模糊,因此现在来理解一些 U-Net 模型的细节。
首先看 U-Net 的整体架构:
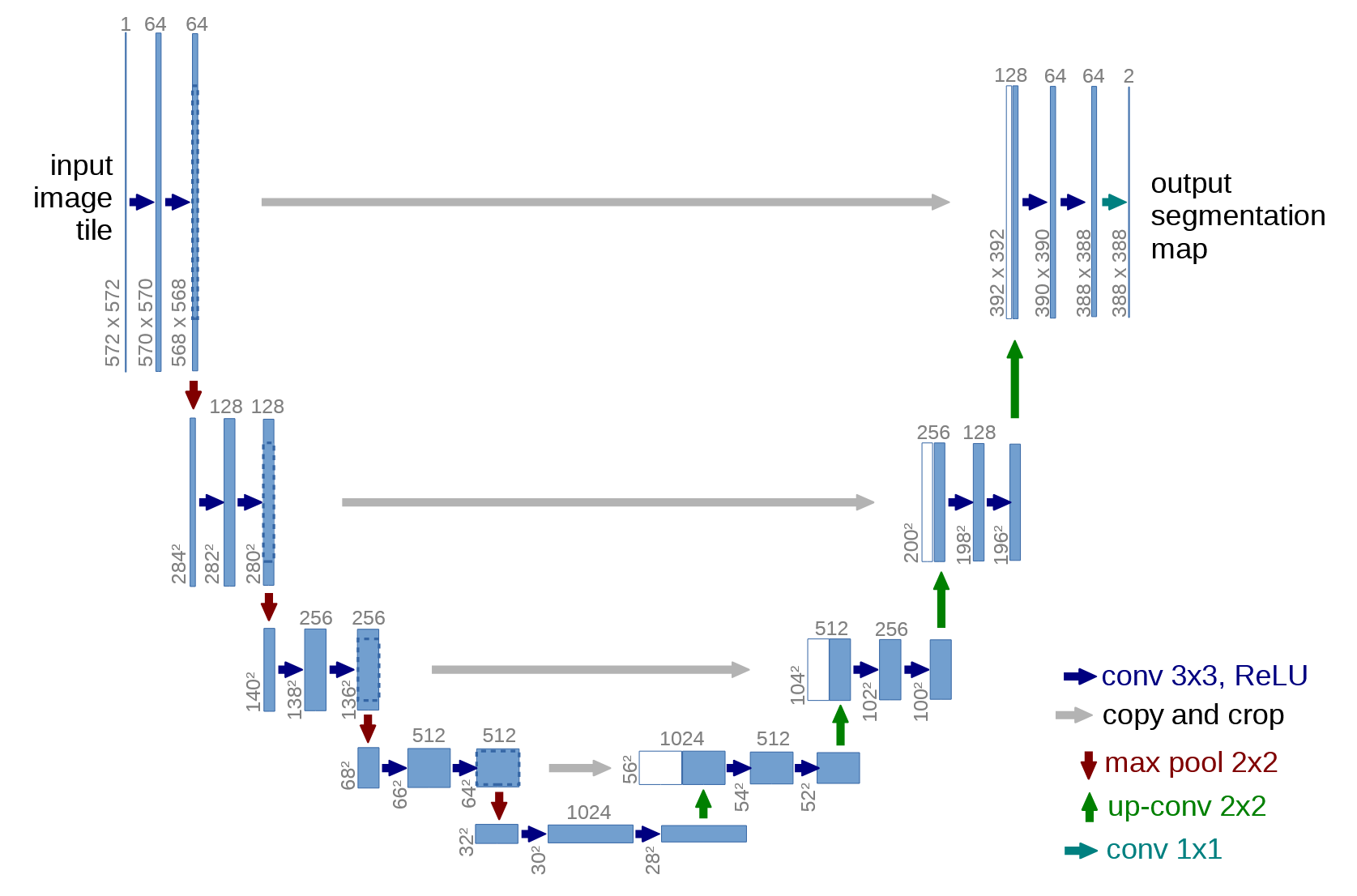
不难发现分成两部分:下采样和上采样。
接下来我们结合代码进行理解细节。
如何下采样?
下采样的核心任务是,逐步减小图像的分辨率,同时增加特征维度,进而捕获语义信息。
1 | |
其实也就是 CNN 里面很常见的操作,代码也很好理解。但是由于我在最初学习的时候就有些混乱,这里重新梳理一下。
核心的代码是 nn.Conv2d(in_ch, out_ch, kernel_size=3)
,意思就是说,我的卷积核大小是 3 * 3 的长和宽,然后高是
in_ch
,每个卷积核会对每一个通道进行卷积操作,然后不同的输入通道会相加,进而得到一个单一的特征平面,进而起到压缩图像分辨率,提取语义的作用。这样的卷积核有多少个呢?也就是有输出通道
out_ch 个。
然后 nn.ReLU(inplace=True)
起到激活函数的作用,并不会改变特征图的大小和维度。
最后是一个池化层,池化层
nn.MaxPool2d(kernel_size=2, stride=2)
并不会改变通道数,只会改变尺寸,作用就是保留更加重要的语义信息,增强平移不变性。
直观理解,下采样是一个“视野变大,信息变浓缩”的过程。
如何上采样?
上采样负责逐步恢复图像的分辨率,然后结合左侧的精细特征。
1 | |
然后与下采样不同,下采样是先进行卷积操作,再进行 down 操作,然后上采样反过来,先进行 up 操作,再进行卷积操作。
首先让我们聚焦这行代码:nn.ConvTranspose2d(in_ch, out_ch, kernel_size=2, stride=2)
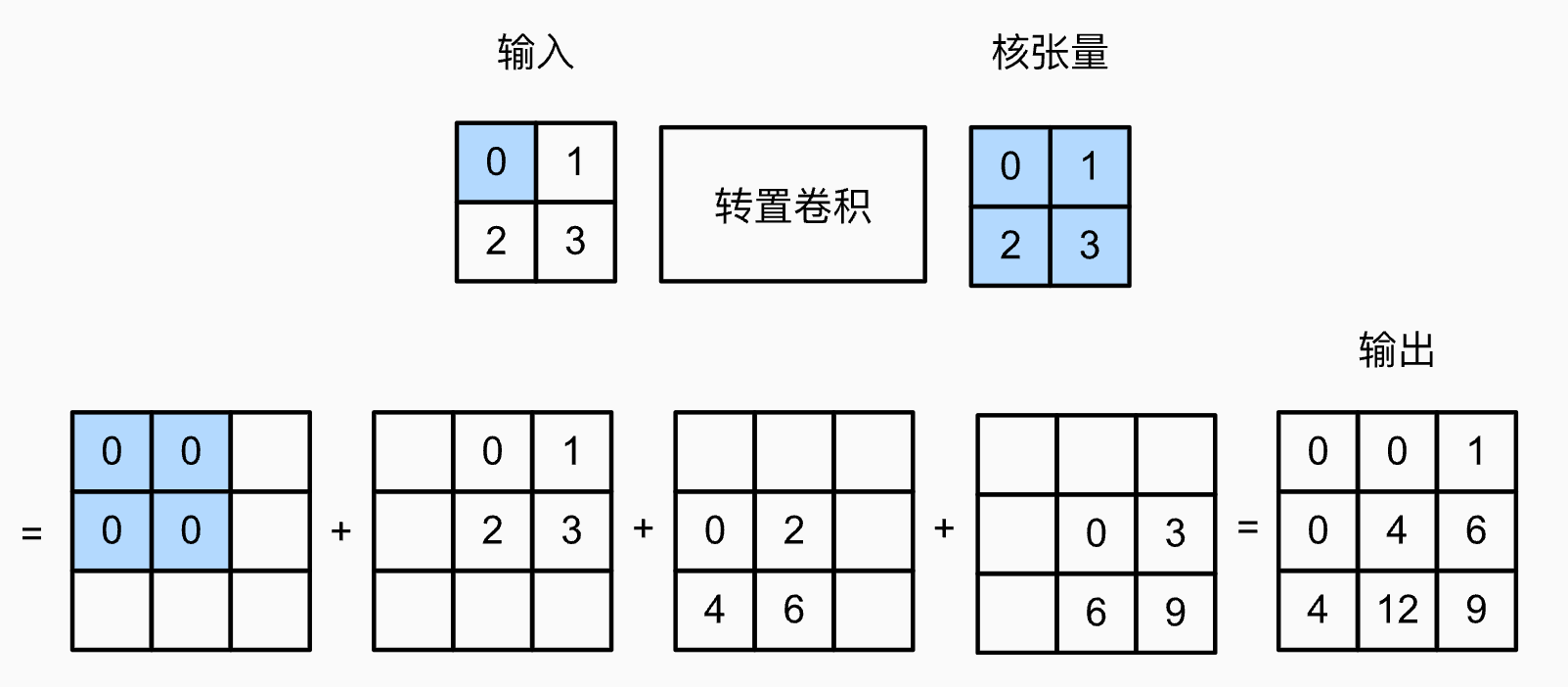
,这行代码实现了上卷积(转置卷积)操作。普通的卷积是为了把图像变小,变厚,进而提取深层语义特征;而转置卷积则是为了把图像变大变薄,进而恢复空间细节。
对于转置卷积,用李沐老师的图更好理解:
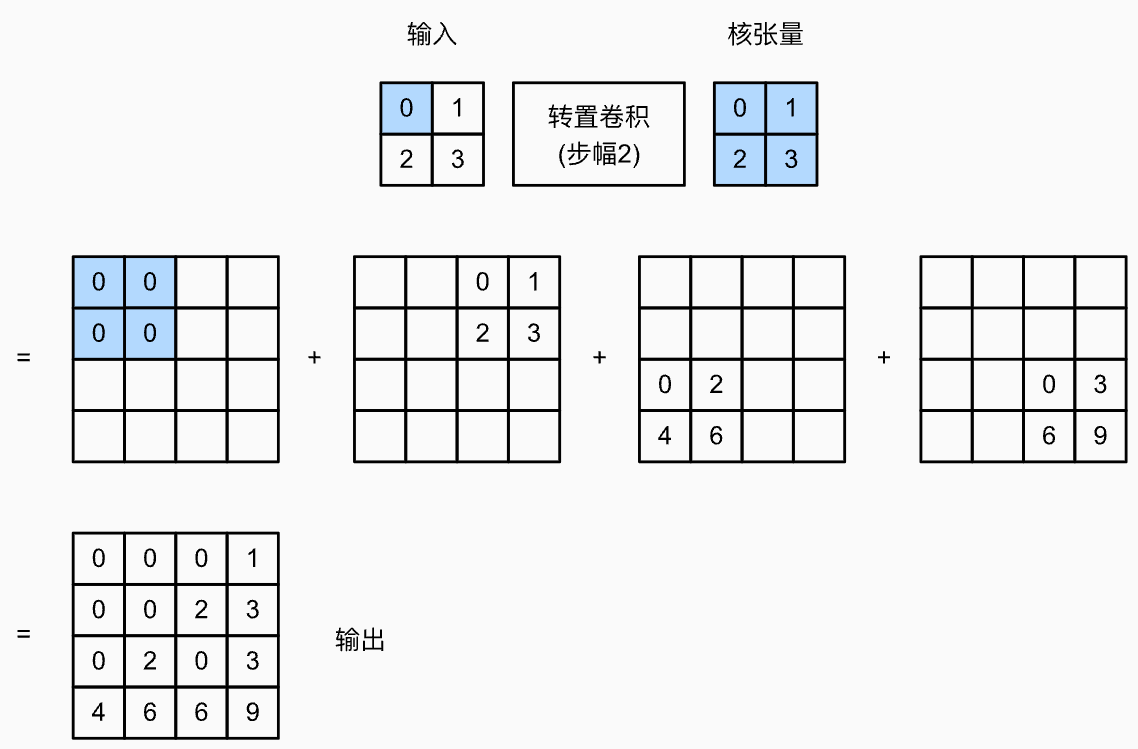
如果 stride = 2:
资料:
- 图:https://zh-v2.d2l.ai/chapter_computer-vision/transposed-conv.html#sec-transposed-conv
- 视频:https://www.bilibili.com/video/BV17o4y1X7Jn?t=6.9
为什么左右看起来不太对称?
仔细看之前的 U-Net 图,会发现有一些细节,左侧的特征图似乎总是比右侧大一圈,原因是左侧并没有使用 Padding。
就比如,左侧的特征图大小,从 8 变成 6,然后减半变成 3, 到达最下侧,变成 2,然后再上采样,就变成了4,比左侧小。
因此就需要对左侧的特征图进行裁剪:
1 | |
核心直觉是原作者认为 Padding 会引入噪声,但是在现代实现里,往往会加上 Padding。