StereoCrafter
Paper:StereoCrafter: Diffusion-based Generation of Long and High-fidelity Stereoscopic 3D from Monocular Videos,2024
论文解决的核心问题:如何把普通的 2D 视频转换成 3D 电影院那种 3D 视频。
要解决这个问题,存在如下困难:
- 虽然我们含有大量的 2D 视频数据,但是极度缺乏 3D 视频数据。
- “空洞”难题。当我们稍微移动画面中的物体时,原来物体挡住的背景就会空出来一部分,这一部分必须画出来。
- 复杂场景失效。在面对烟雾,火或者高速物体时,效果很差。
- 很多方法只能生成几秒钟的低分辨率片段,无法处理长电影。
论文是如何解决的?
首先第一步是深度感知变形。就是预测视频中每个物体的深度,然后把左眼看到的像素推到右眼该看的位置。以下图为例:

论文使用了 DepthCrafter 和 Depth Anything V2 这两个深度估计模型,进而能够估计每个物体的深度。在得到深度后,如何才能知道该偏移多少像素呢?
在立体视觉几何中,深度
其中
在推像素的时候,可能会遇到多个像素重叠在一起,比如上图的树叶和墙,这个时候论文使用了如下的公式,为每个移动的像素计算一个权重。
系统选择权重最大的像素来决定颜色。
在移动完像素后,出现一个问题,有的像素被移动走了,但是原来的位置没有像素移动过来。因此论文使用了视频扩散模型用于立体视频补全。
为了解决长视频场景和高分辨率的问题,论文设计了两套策略:
- 自回归:处理完前几秒,把结果喂入下几秒。
- 分块处理:把高清画面切成小块处理再缝合。
整体的 Pipline 如下图:
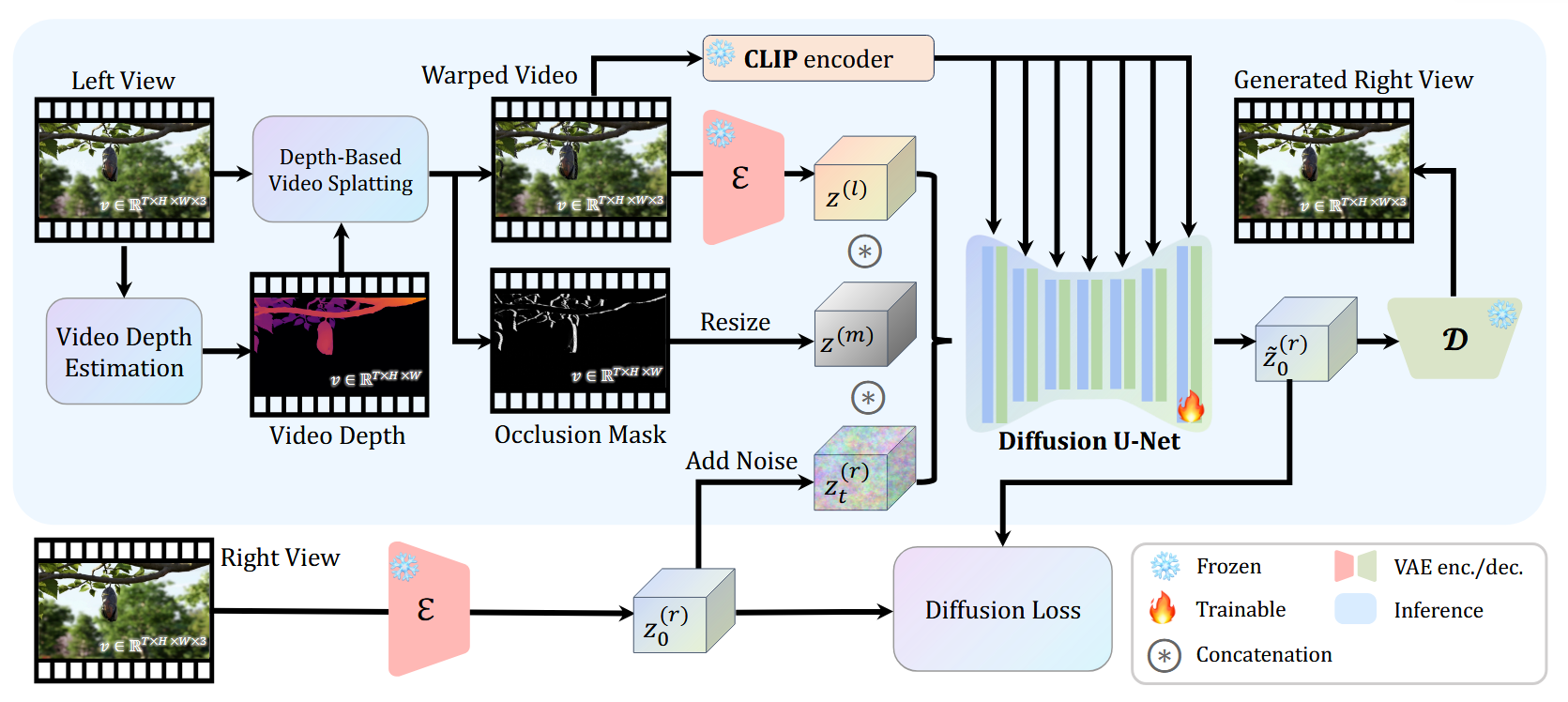
首先输入左视图,然后经过深度估计模型 Video Depth Estimation 估计深度,然后再利用深度信息进行像素偏移(Depth-Based Video Splatting)。会生成两个东西:
- 偏移后的图。
- 空洞掩码。
然后偏移后的图经过 VAE 编码器
然后经过 Diffusion 补全,得到隐空间特征
在实验规模方面,论文收集处理得到 18 万条训练序列,总计 2500 万帧图像。使用了 8卡 A100 GPU。