StereoWorld
Paper:StereoWorld: Geometry-Aware Monocular-to-Stereo Video Generation,2025
这篇论文解决的还是 2D 视频如何重建成 3D 视频的问题。论文认为传统方法(深度估计+畸变填充)容易导致纹理扭曲,颜色漂移的问题。那么论文是怎么解决的呢?
把左右眼画面视作一个视频序列。我们先看论文的整体 Pipline 图:
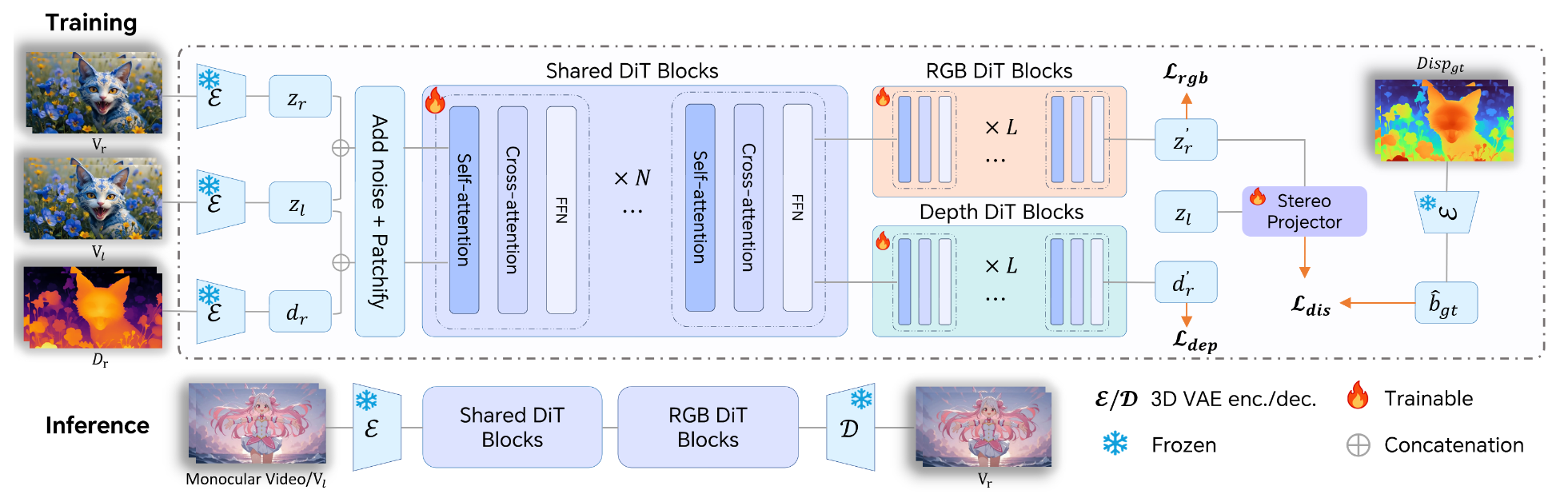
首先把三张图通过 VAE 转换为潜空间表示:
- 左视图
- 右视图
- 右视图的深度图
Diffusion 的输入是左视图的潜空间表示,前面共享了一些 DiT Blocks,在最后几层,分别预测两个目标:
- 预测右视图。很显然,我们需要预测这个。
- 预测右视图的深度图。注意这个只有在训练的时候才有,能够让模型理解深度边界,确保生成的物体有立体感。
那么论文的损失函数是如何定义的呢?
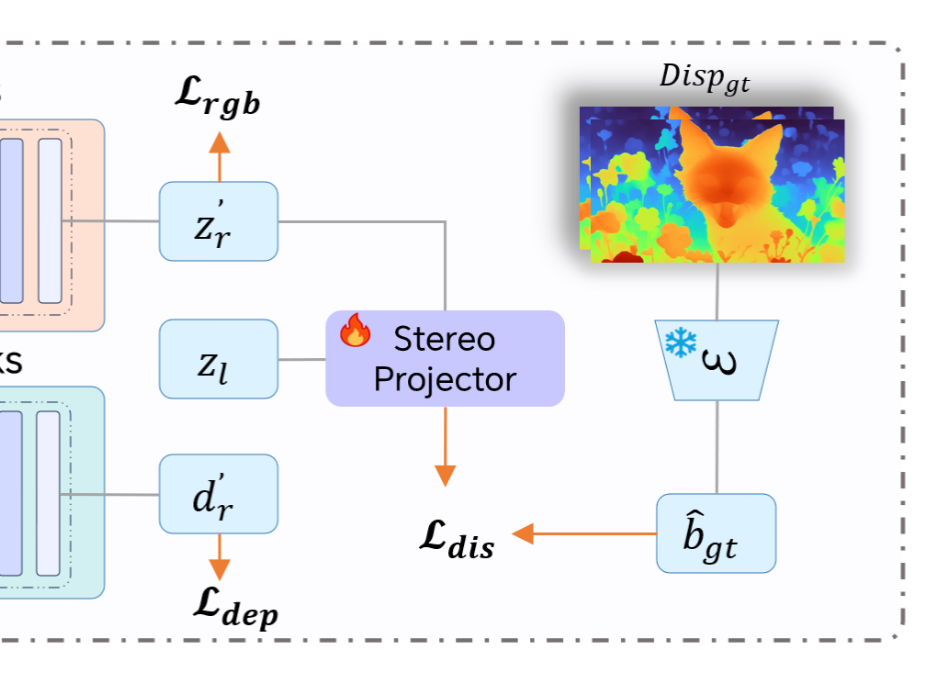
根据上图可以看到有3个。
什么是 RGB 重建损失?本质是一种回归损失,目的是让模型从噪声中预测还原 RGB 信息。
其中:
:扩散过程中的噪声状态 。 :模型预测的“速度场”(即模型认为像素应该往哪个方向变化) 。 :真实的演化路径(即从噪声到真实画面的正确方向) 。
同理,预测深度图的损失为:
但是论文认为还是不够,还引入了视差的 Loss:
视差整体的 Loss 可以分成两部分。
:像素级别的精准约束。 ,里面的两个符号一个是真实的视差值,一个是预测的视差值。 - 确保每个物体的位移是精准的。
:全局的几何一致性。 ,其中 - 并不关注单个像素的对错,而是关注整幅画的结构。
:权重调节器。
StereoWorld
https://d4wnnn.github.io/2026/03/15/Notion/StereoWorld/