Eye2Eye
Paper:Eye2Eye: A Simple Approach for Monocular-to-Stereo Video Synthesis
传统方法往往采用深度估计+平移+图像修复的流水线,但是这些方法往往假设像素只有单一的深度值。但是当场景中存在透明物体或者镜面反射,一个像素点实际上融合了不和深度的信息,比如:
- 玻璃表面的深度
- 玻璃中倒影的虚像深度
传统方法在这种情况下会产生严重的伪影,导致 3D 效果失真。
因此论文放弃了显示的几何估计,直接用预训练的视频扩散模型的先验知识来合成新视角。
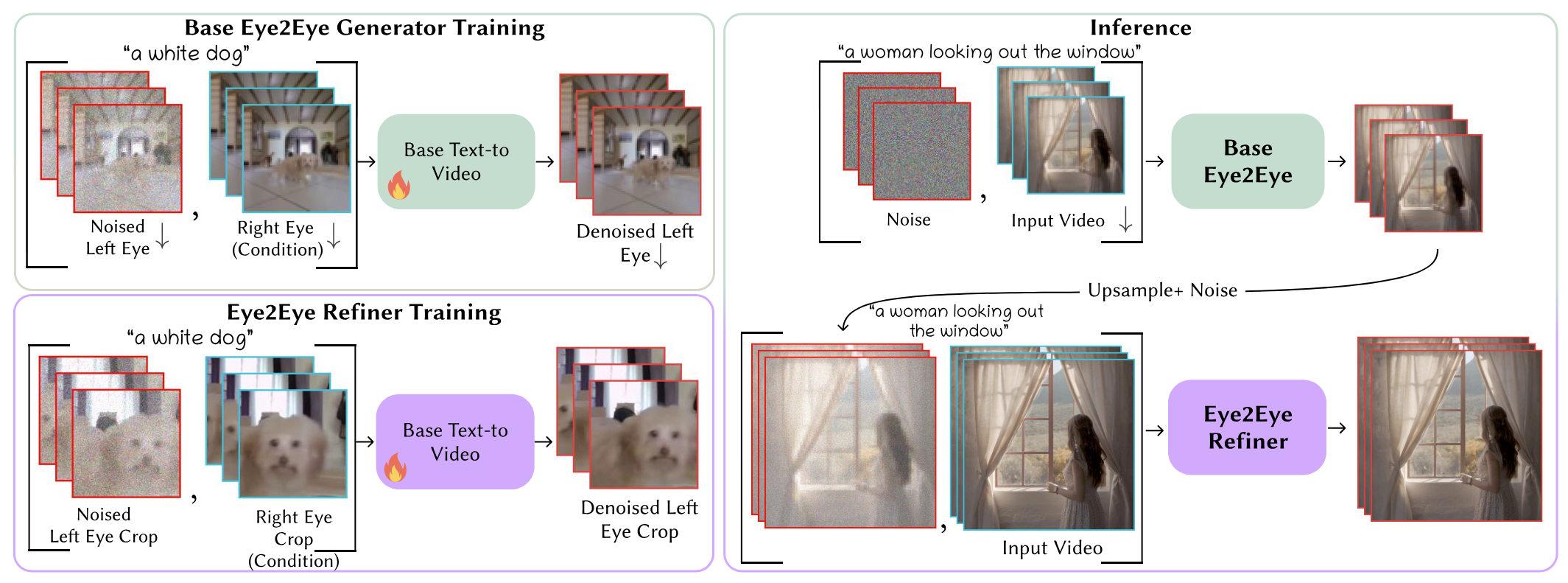
论文的方法如上,为了解决训练分辨率和推理分辨率的矛盾,论文首先从低分辨率下训练(画一个草图),确定左右眼的位移比例。然后对低分辨率图片上采样并加入噪声,在高清局部切片上训练的精炼模型去去噪。
然后模型在 Stereo4D 数据集上微调,利用模型的隐式先验来处理复杂的非朗伯体(Non-Lambertian)光效。
什么是郎伯体?就是从任何角度观察,物体的亮度都一样,比如白纸。
论文使用的模型是什么?
- Base Eye2Eye Generator
- Eye2Eye Refiner
二者都是基于 Lumiere
效果如下:

Eye2Eye
https://d4wnnn.github.io/2026/04/15/Notion/Eye2Eye/