Voyager
Paper:Long-Range and World-Consistent Video Diffusion for Explorable 3D Scene Generation,TOG,2025
论文解决了在利用单个图像进行长距离、可自由探索的3D场景视频生成时,存在的核心挑战:
- 长距离生成的空间不一致性:进行长距离镜头轨迹移动时,难以保持场景的几何连贯性。
- 视觉幻觉:单纯依赖部分RGB图像作为条件引导视频生成,在复杂遮挡场景下极易产生错误的视觉内容。
- 效率低。传统方法需要先生成视频,再通过复杂的后处理重建 3D 场景。
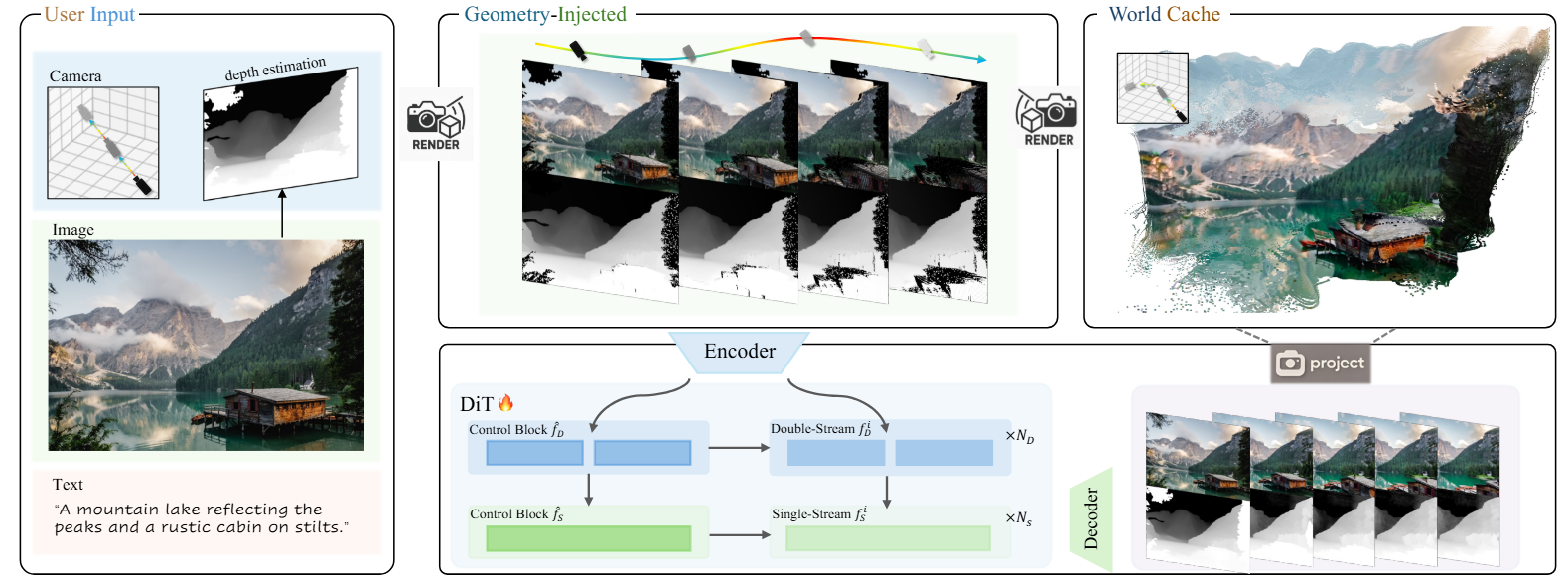
论文框架如上。
首先模型的输出除了 RGB 图像外,还有深度图。将深度图和 RGB
图像进行反投影构建 3D 点云
反投影:从 2D 图像到 3D 空间。
然后根据新视角的相机参数
- 如果
对应位置有值,模型就遵循该信息生成像素。 - 如果
对应位置没有值,模型就需要生成。
因此核心逻辑是先建立几何底座,再进行像素生成。

然后论文将深度信息和 RGB 信息在高度方向进行拼接,中间加一个占位行,利用 DiT 的全局注意力机制进行交互。
另外为了实现长距离、甚至理论上“无限”的场景探索,Voyager 还引入了如下的创新点:
随着新视频的生成,系统会增量将新帧的 RGB 和深度图反投影成 3D 点云,并存入世界缓存。为了缓解存储压力,对于已经存在的点,如果它于当前视角的表面法线夹角超过90(意味着不可见),就剔除这些点,缓解存储压力的同时能够避免多帧叠加带来的噪声积累。
为了避免视频闪烁,论文进行了平滑采样,也就是将上一个片段的生成结果作为噪声初始化的起点。然后:
- 在完成两个连续片段的推理后,系统会在重叠区域进行加权平均处理。
- 然后在重叠的区域注入轻微的噪声,进行去噪推理。
训练数据怎么来的?
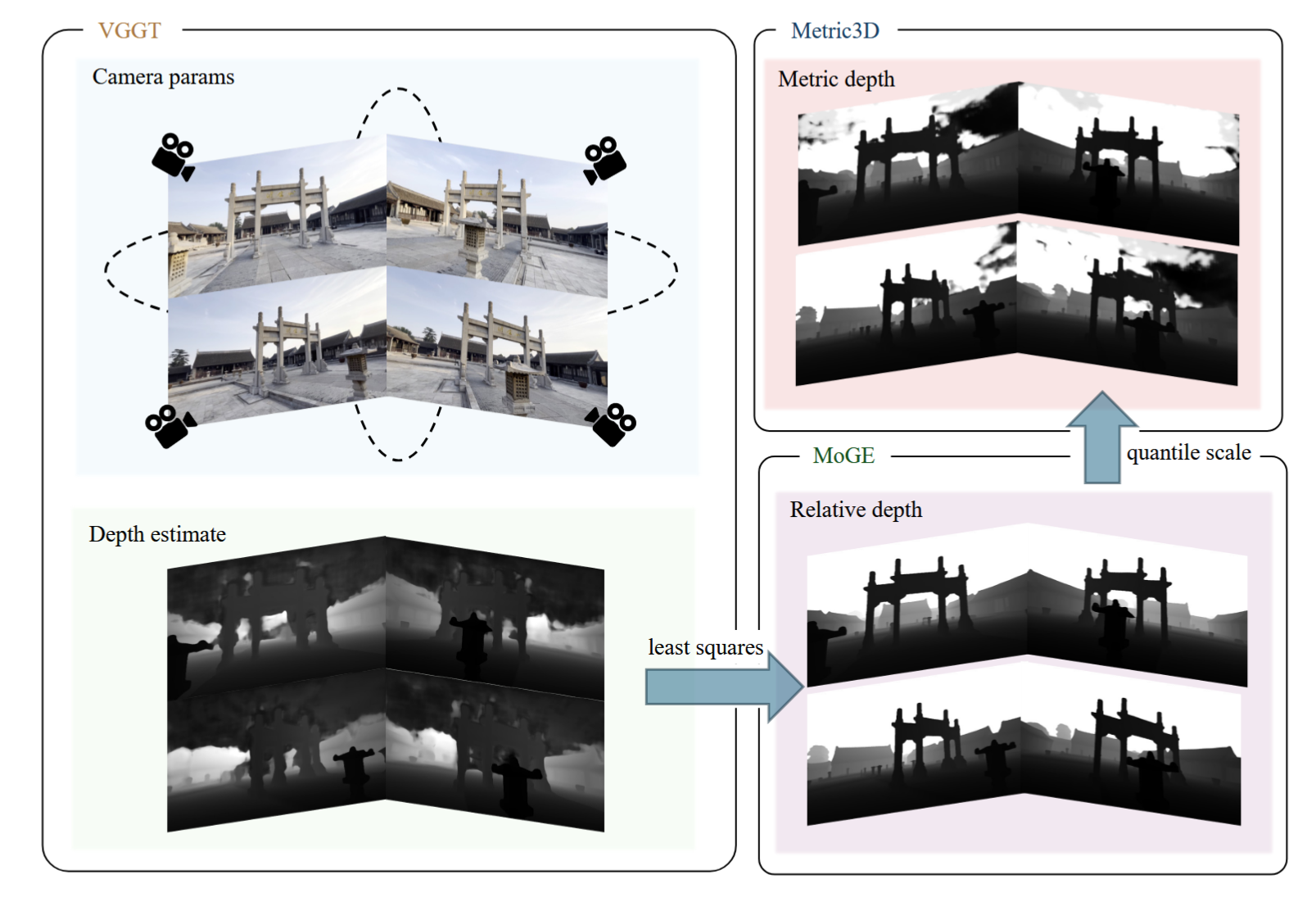
原始内容:普通视频
- 第一步:把普通视频丢给 VGGT 模型,自动跑出每一帧的相机姿态(外参)和一版粗糙的深度图。
- 第二步:把视频丢给 MoGE 模型,生成一版边缘极其清晰、质量极高的深度图(但它只有相对远近,跟第一步的相机姿态不对齐) 。然后用最小二乘法优化 ,强行把 MoGE 的高质量深度缩放对齐到 VGGT 的相机姿态上 。
- 第三步:把视频丢给 Metric3D 模型,测出场景的现实物理尺寸范围(绝对度量),通过分位数映射,把前两步统一好的深度图全部变成标准一米、两米的真实物理尺度深度 。
最终获得十万条对齐数据。
是怎么训练的?
数据:视频+相机姿态+绝对深度。
- 第一步:基础视频模型的 RGB 视角控制训练
- 冻结大部分结构,只输入“第一帧图片 + 相机轨迹 + 目标视频的残缺 RGB 图像(用点云投影过去的遮挡视角的残缺图)” 。
- 其实也就是说,将第一帧的图片得到点云,根据第 k 帧的深度重新投影到第 k 帧的平面。
- 这一阶段主要是让模型学会正确的平移和旋转。
- 数据集:全部3个数据集,RealEstate + DL3DV + UE,> 100,000 个视频片段
- 第二步:几何与视觉的深度融合训练
- 把数据集里的 RGB 视频和深度视频在高度方向上拼成一张大图,送进 DiT。
- 让网络同时去预测未来的 RGB 帧和 Depth 帧。
- 数据集:只使用 RealEstate + UE,约 85,000 ~ 90,000 个视频片段
- 第三步:精准空间控制网络训练
- 冻结前两步训好的所有基础网络参数,在旁边外挂两个轻量级的控制块。
- 专门塞入大范围视角变动时渲染的残缺 RGB-D 条件,只训练这两个外挂块。
- 数据集:仅使用 UE 合成数据集,约 10,000 个视频片段
简单总结
Voyager 的整体流程可以概括为:
- 给定一张输入图像、文本 prompt 和用户指定的一段相机轨迹。
- 模型首先对输入图像估计深度,并将 RGB-D 信息反投影到 3D 空间,形成初始的 world cache/点云;随后,根据该相机轨迹,将当前 world cache 分别投影到每个目标相机视角,得到一段与目标视频长度对齐的 partial RGB-D 条件视频,其中已观测区域提供外观和几何约束,未观测区域为空洞;
- 视频扩散模型以输入图像、文本、相机轨迹对应的 partial RGB-D 条件视频和 mask 作为控制条件,一次性生成完整的一段 RGB-D 视频;生成后的 RGB-D 帧再结合对应相机位姿反投影回 3D,并通过 point culling 更新 world cache,从而为下一段自回归生成提供新的世界记忆,实现长距离、空间一致的可探索 3D 场景生成。
Voyager
https://d4wnnn.github.io/2026/04/22/Notion/Voyager/