LingBot-VA
Paper:Causal World Modeling for Robot Control
传统的 VLA 模型普遍采用端到端的范式(直接从观测映射到动作),这种做法存在表征纠缠问题,模型被迫在同一个神经网络中学习复杂的视觉理解,物理规律和电机控制,导致以下瓶颈:
- 样本效率低:缺乏对环境演化和物理规律的显式建模。
- 长程任务失效:容易丢失记忆。
- 因果关系混乱:现有的分块生成方法往往采用双向注意力,违背了物理世界现在仅取决于过去的因果时序。
论文没有将视频和动作分开处理,而是直接当作一个统一的序列。
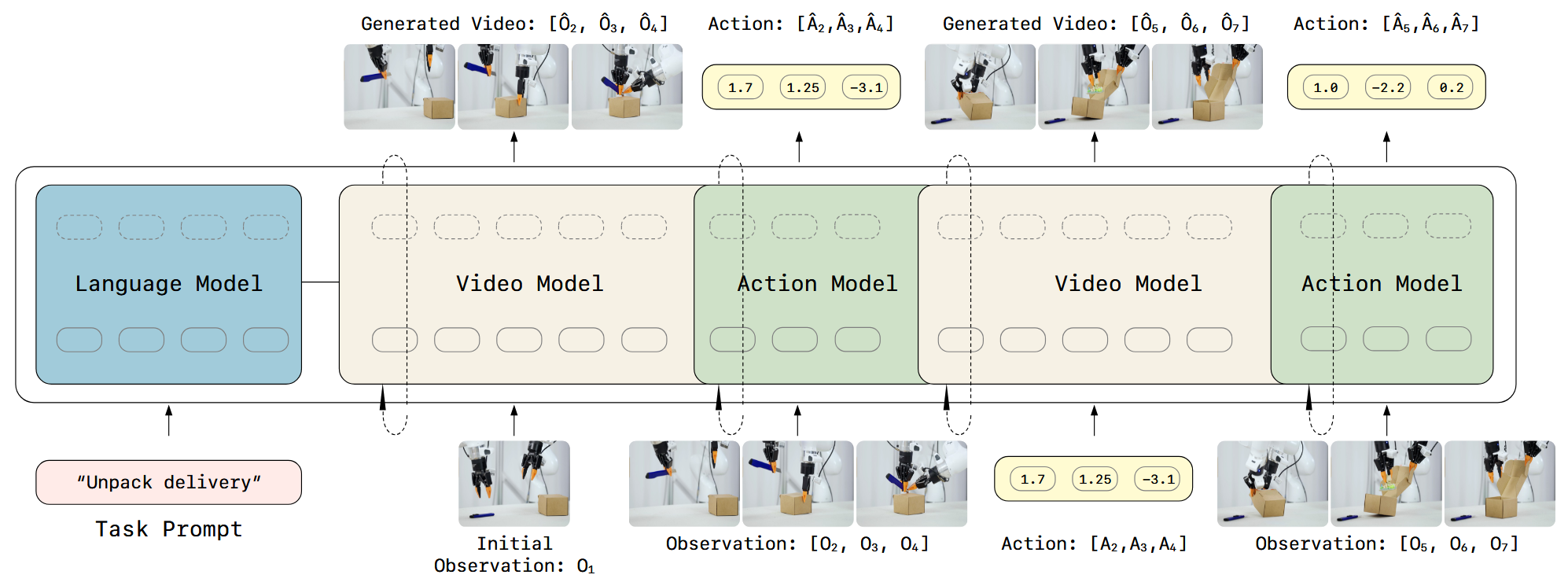
论文采用 Mixture of Transformers 双流架构分别建模视觉特征和动作特征,并通过跨模态注意力进行融合。
优化公式:
其中
在机器人控制中,为了保证实时性,模型通常需要预测未来一段轨迹的动作或视觉状态。
- 如果“逐帧生成”:模型每预测一个动作,就需要运行一次完整的神经网络计算。对于复杂的视觉模型,这会产生巨大的计算压力,导致机器人反应迟钝 。
- “分块生成”策略:模型不再是一次只预测一个时间点的动作,而是一次性预测未来
个时间点的视频或动作序列 。这 个数据点被统称为一个“块(Chunk)” 。
分块生成主要是为了在“生成质量”和“计算效率”之间寻找平衡点。
整体的 Pipeline 如下:

LingBot-VA
https://d4wnnn.github.io/2026/04/25/Notion/LingBot-VA/