E-DiT
Paper:Elastic Diffusion Transformer
论文核心框架
解决的核心问题:DiT加速。
方法框架图。
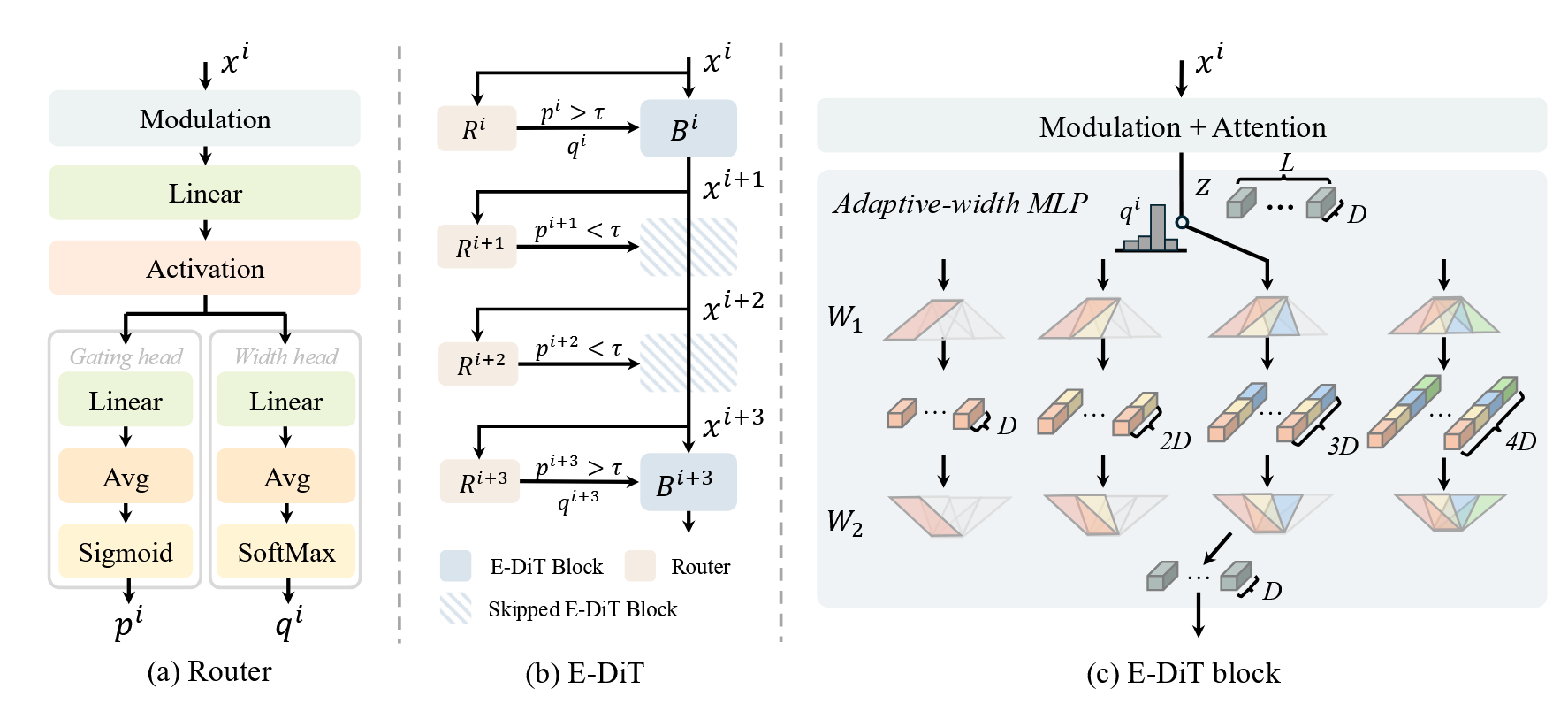
核心组件1:自适应跳过层
- 为每个 Transformer 块配备一个轻量级“路由”(Router)。路由会根据当前输入的潜变量和时间步,预测该块是否可以被完全跳过而不影响质量。
核心组件2:自适应 MLP 宽度缩减
- 对于没有被跳过的块,路由会进一步预测该块内 MLP 层的最佳宽度比例(如 1/4, 1/2, 3/4 或 1),从而按需分配计算资源。
核心组件3:块级特征缓存
- 这是一种免训练的推理加速手段。当路由预测某个块处于“边缘区域”(即贡献较小但未达到跳过阈值)时,直接复用前一时间步的特征残差,进一步消除冗余计算。
研究人员在 2D 图像生成(Qwen-Image、FLUX)和 3D 资产生成(Hunyuan3D-3.0)等多个主流模型上进行了验证:
- 加速效果: 在几乎不损失生成质量的前提下,实现了约 2 倍 的推理提速。
- 通用性: 证明了该框架可以广泛应用于不同的 DiT 骨干网络和模态。
论文如何训练 Router?
Router 的任务是根据输入特征输出几个离散决策概率(比如跳过概率 argmax 选出概率最大的那个宽度。
然而 argmax 操作是没有梯度的,无法通过反向传播更新
Router 的参数。为了解决这个问题,训练采用Gumbel-Softmax 松弛。
不同宽度的 MLP 如何训练?
比如模型有 0.25, 0.5, 0.75, 1.0 四种宽度,难道要训练四个不同的 MLP 吗?
答案是:不需要。它们训练的是同一个 MLP,采用的是“权重嵌套(Weight Sharing/Slicing)”机制。
这是借鉴了可瘦身神经网络(Slimmable Networks)的理念:
- 物理切片与嵌套: 0.25 宽度的模型参数,并不是独立的,它就是 1.0 宽度模型参数的“前 25%”。0.5 宽度的参数则是“前 50%”。所有的宽度候选集都在一个完整的权重矩阵内。
- 非对称的梯度更新:
- 当 Router 决定当前 Token 使用 0.25 的宽度时,前向计算只调用矩阵的前 25%,反向传播时,也只有前 25% 的权重会获得梯度更新。
- 当 Router 决定使用 1.0 的全宽度时,整个矩阵的所有参数都会参与计算并获得更新。
- 训练结果:由于这种嵌套更新机制,MLP 矩阵的前 25% 参数(头部)在几乎所有的选择中都会被用到,因此它们被更新得最频繁,被迫学会了提取最核心、最基础的视觉特征(比如大轮廓、低频信息)。而矩阵后段的参数(尾部)只有在需要精细刻画(如复杂纹理、文字)时才会被激活更新,从而变成了专门处理高频细节的“专家”。
实验结果
总体表现
在所有测试的基准上,E-DiT 实现了最高约 2倍 (2×) 的实际推理速度提升。
最关键的是,与传统的静态剪枝(Static Pruning)或模型蒸馏(Distillation)不同,E-DiT 在算力大幅减半的同时,生成的画质、语义对齐度等核心指标几乎没有任何可以感知到的下降。
消融实验
- 自适应跳过层 + MLP 缩减(需要微调): 奠定了主要的加速基础,Router 成功学到了在不关键的层和简单的 Token 上“偷懒”。
- 块级特征缓存(Block-wise Caching,免训练): 实验表明,当把这个技术叠加到已经训练好的 Router 上时,它能在推理阶段无缝地榨干最后一丝计算冗余。它利用 Router 的预测结果,直接把“食之无味弃之可惜”的边缘计算块变成缓存复用,让加速比进一步冲向 2×。
Router 的决策可视化
- 时间步(Timestep)层面的自适应: 在去噪的早期阶段(Noise 很大时,模型主要在确定画面的宏观构图和低频轮廓),Router 大面积激活了“跳过层”和“0.25/0.5 窄宽度 MLP”;而在去噪的中后期阶段(开始雕刻细节),Router 自动切换回了“1.0 全宽度”。
- 样本复杂度(Sample Complexity)层面的自适应: 处理一张“干净、纯色背景”的简单图片时,Router 极度省算力;而处理一张“带有复杂文字、高密度纹理”的困难图片时,Router 会非常自觉地分配全额算力。
E-DiT
https://d4wnnn.github.io/2026/05/17/Notion/E-DiT/