EfficientVLA
Paper:EfficientVLA: Training-Free Acceleration and Compression for Vision-Language-Action Models,NeurIPS 206
论文解决的核心问题:免训练的推理加速与压缩框架。
VLA 模型把视觉、语言和机器人动作生成结合起来,适合机器人操作任务。但扩散式 VLA 通常包含:
- 视觉编码器:处理图像;
- 语言模型 / VLM 主干:做多模态理解和推理;
- 扩散式动作头:多步去噪生成机器人动作。
问题是:这些模块推理成本很高,尤其是 LLM 语言模块 和 扩散动作头,导致模型难以部署到真实机器人或边缘设备上。
论文指出,单独优化某一个模块往往效果有限,因为瓶颈会转移。例如只裁剪视觉 token,前期能减少计算,但后续很快会被 LLM 的内存瓶颈限制。
核心方法
语言模块:基于层冗余的非连续层剪枝
- 作者发现 LLM 不同层之间存在明显冗余:很多层的输入和输出 hidden states 余弦相似度很高,说明这些层对表示的改变很小。
- 如果某层输入和输出越相似,说明它越不重要,越适合剪掉。
- 与普通连续剪枝不同,EfficientVLA 使用 non-contiguous layer pruning,也就是根据重要性排序,直接移除最不重要的若干层,而不是简单剪掉最后几层。
- 结果上,CogACT 的语言模块参数从 6.74B 降到 3.97B,语言模块推理时间从 134.5 ms 降到 58.9 ms。
视觉模块:任务相关性 + 多样性的 token 选择
- 视觉 token 中存在两类冗余:
- 与任务无关的 token;
- 与其他 token 信息高度重复的 token。
- 首先,通过 attention 分数找出与语言指令最相关的 key task-relevant tokens。例如“move blue plastic bottle near pepsi can”时,模型应该保留与蓝色瓶子、百事罐等目标相关的视觉区域。
- 然后,在剩余 token 中,一部分继续按任务相关性选,另一部分按特征多样性选,避免所有 token 都集中在相似区域。
- 最终视觉 token 可从 256 个压缩到 56 个,但仍保持较高任务成功率。
动作模块:扩散去噪过程中的中间特征缓存
- 扩散动作头需要多步去噪,每一步都会重复计算 attention 和 MLP。作者观察到相邻扩散 timestep 的中间特征非常相似,说明存在时间冗余。
- 因此 EfficientVLA 设置固定缓存间隔 N:
- 第一次或每隔 N 步重新计算 attention / MLP;
- 中间步骤直接复用缓存结果;
- 从而跳过大量重复计算。
- 论文中 cache interval 设为 5,使动作模块 FLOPs 从 57.96G 降到 11.72G,推理时间从 51.5 ms 降到 26.2 ms。
实验结果
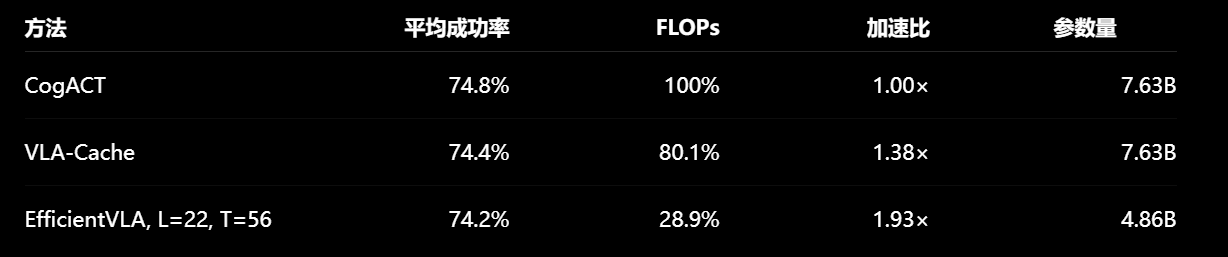
消融:单独视觉 token 剪枝可以把速度提升到 1.25×,但很快受限于语言模块瓶颈。单独动作缓存可以达到 1.23×。语言层剪枝 + MLP 压缩能达到 1.43×。
EfficientVLA
https://d4wnnn.github.io/2026/05/18/Notion/EfficientVLA/