Fast-WAM
Paper:Fast-WAM: Do World Action Models Need Test-time Future Imagination?
这是一个新的研究领域:世界模型。
目前的世界动作模型(World Action Models,WAMs)通常遵循先想象再执行的范式,也就是先生成未来画面,再根据画面决定怎么动,但是存在两个问题:
- 太慢,毕竟生成视频。
- 必要性存疑:WAN带来的性能提升,究竟是推理看到了未来,还是仅仅因为训练时学过视频预测?
世界动作模型存在如下几种范式:
- 范式 A:联合预测,同时对未来视频帧和动作序列去噪处理。
- 范式 B:因果预测,首先生成未来视频帧,然后再作为输入,通过动作预测模块产生动作。
- 范式 C:Fast-WAM,训练仍然预测未来视频,推理时只利用视频的 Backbone 对当前观察做一次前向传播。

因此论文提出 Fast-WAM,训练保留预测未来视频的任务,强迫模型学习物理世界的规律;但是在推理的时候,把预测未来的步骤去掉。

为了实现上述解耦,模型采用了 Mixture-of-Transformer(MoT)架构,包含一个视频 DiT 和一个动作 DiT。
论文使用 Flow Matching 作为训练目标,让模型学习如何从噪声中还原动作和视频。损失函数如下:
其中
实验结果如下:
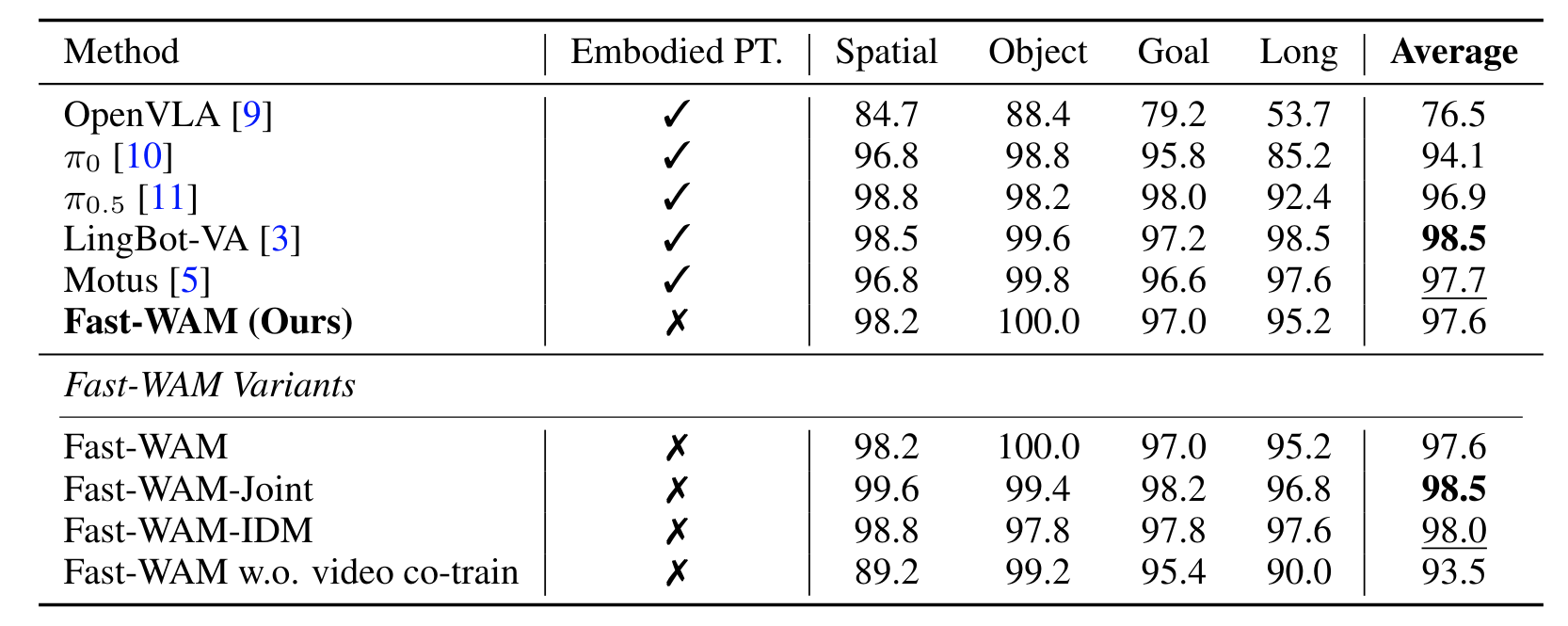
其中:
- Fast-WAM (Ours): 训练时有视频联合建模,推理时不生成视频 。
- Fast-WAM-Joint: 对应“联合生成”范式,推理时视频与动作同时生成 。
- Fast-WAM-IDM: 对应“先生成视频再做动作”范式 。
- Fast-WAM w.o. video co-train: 直接删掉训练时的视频建模目标,作为纯策略基准 。
Fast-WAM
https://d4wnnn.github.io/2026/04/18/Notion/Fast-WAM/