\pi^3-3D重建
Paper:
在传统的视觉几何重建(如MVS)以及现在的深度学习模型(如DUSt3R)中,通常需要指定一张图片作为基准,其他的相机位置都基于这个基准来算。
存在的问题:引入了不必要的归纳偏置,比如选中的参考帧拍模糊了,光线不好,整个重建质量就会很差。因此模型对于输入的图片顺序非常敏感,鲁棒性差。
因此论文设计了一个在输入顺序上完全对称的网络,也就是无论输入顺序是什么,输出的 3D 结果是一致的。
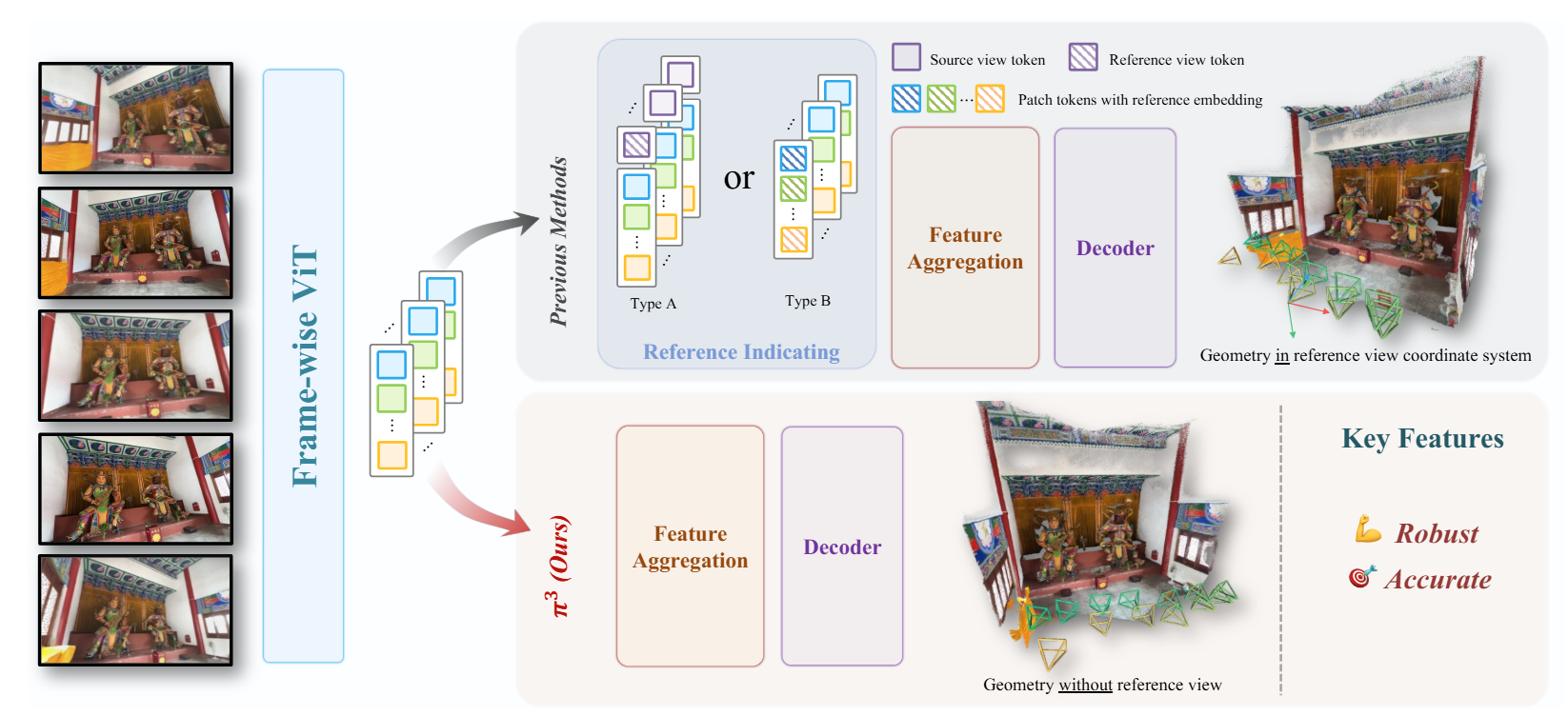
通过框架图可以看到传统方法和论文方法的区别:
- 传统方法(上半部分)
- Type A:在图像序列中,给参考帧添加一个额外的标识Token。
- Type B:给参考帧的 Tokens 加上可学习的位置编码。
- 论文方法(下半部分)
- 图像经过 ViT 后直接进入特征聚合和解码阶段。
创新点一:丢掉了所有与顺序无关的组件,比如帧索引位置编码和专门代表参考帧的 Learnable Tokens。
创新点二:尺度无关的局部几何。
在单目3D重建中,无法从单张图片获得物体的真实物理尺寸。为了训练网络,必须找到一个最优的缩放因子
其中
为什么要除以深度?将绝对误差转为相对误差,因为远处的物体即使有很小的角度偏差,L1距离也会很大。
创新点三:仿射不变的相机位姿。
监督网络去学习视图
分成两步:
:第一步,把坐标从相机 的视角搬到虚拟世界中心。 :第二步,这是 的逆矩阵,把东西从虚拟世界中心搬回相机 的视角。
下面是一些效果:

\pi^3-3D重建
https://d4wnnn.github.io/2026/04/18/Notion/pi^3-3D重建/