AGILE
Paper:AGILE: Hand-Object Interaction Reconstruction from Video via Agentic Generation
论文在做什么?通过普通的单目视频,精准还原出人操作物体的3D动态过程。

有什么意义?
- 可以将大量的人类操作工具的视频转成高质量3D数据,进而训练机器人。
- 让虚拟现实的显示更加真实。
难点是什么?
- 几何破碎且不闭合。也就是手挡住物体。
- 位姿初始化极其脆弱。也就是物体快速运动会崩溃。
论文是如何解决的?
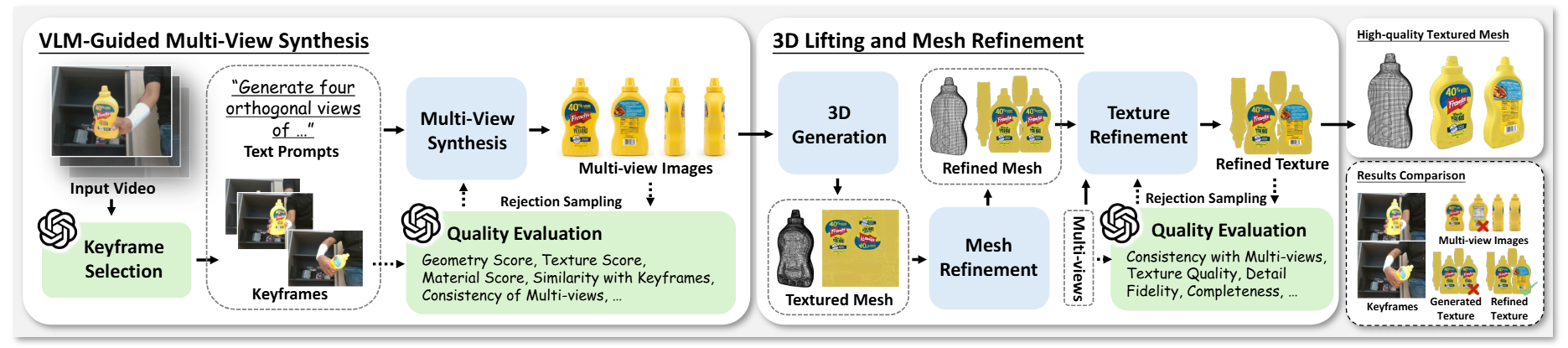
上述图解释了论文的一个核心创新点:智能代理纹理对象生成。
具体可以分成两个步骤:
- VLM 引导的多视角合成。
- VLM 从视频中自主挑选1-4帧最具信息量的关键帧。
- 基于选中的关键帧,生成模型合成物体的四个正交视角(前后左右)。
- VLM 对视角进行评分,未达标则重新生成。
- 3D 提升与网格精炼。
- 通过3D生成模型将图像转成初始3D网格。
- 纹理精炼。恢复物体的高频细节。
- VLM再次进行评分。
另外第二个创新点是免 SfM 的“锚定-追踪”初始化。
传统重建方法高度依赖 SfM(Structure-from-Motion) 技术,通过对比视频的不同帧的相同特征点来推算位置,但是在手持交互物中,物体通常被挡住且移动太快,只要 SfM算错一帧,视频质量就会崩塌。
AGILE会盯着交互起始帧(Interaction Onset Frame,
IOF),也就是手刚碰到物体的那一帧,通过计算物体 Mask 的变化率
这一步用到了基础模型 FoundationPose。在第一阶段我们已经生成了一个完美的 3D 模型,这一步则是对准 IOF 帧的物体,完成初始定位。
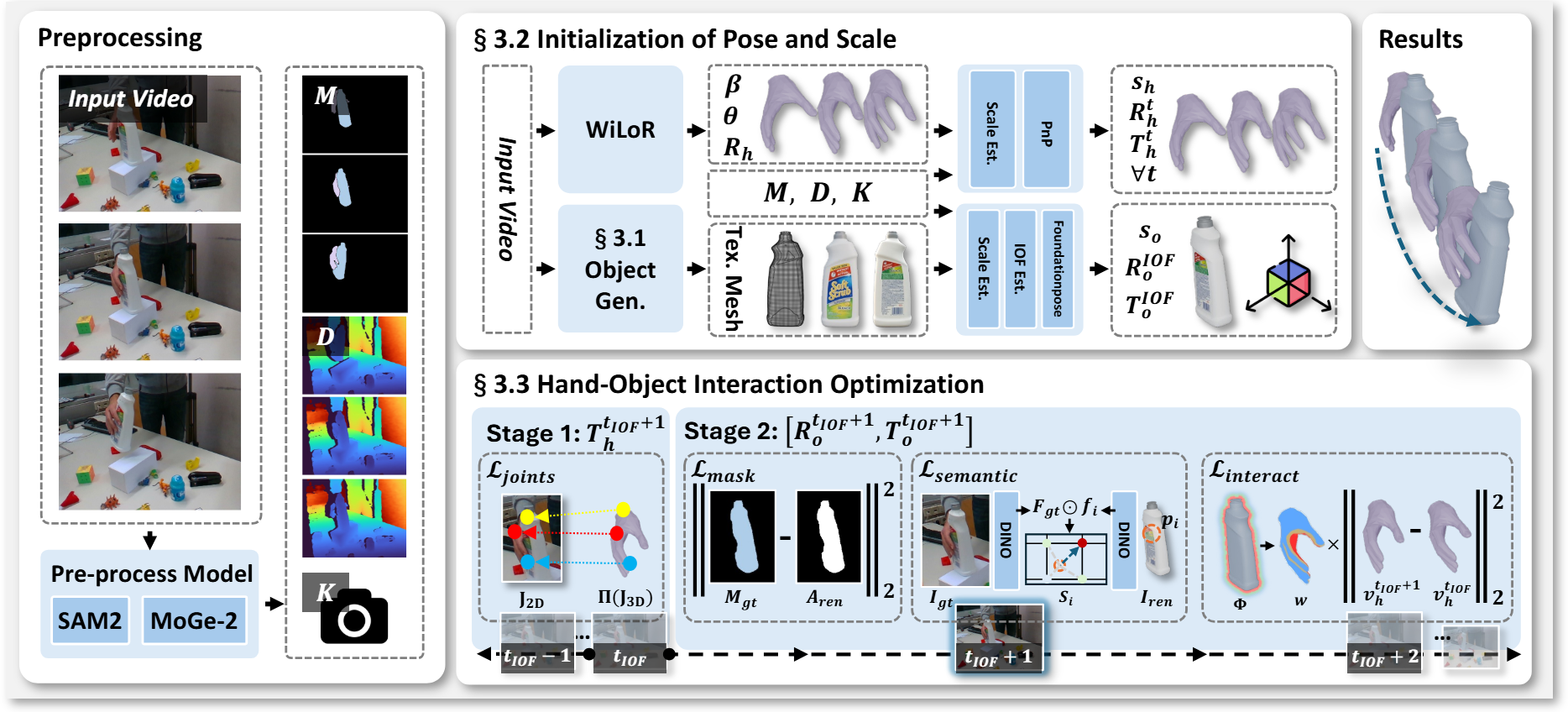
上图可以分成3个阶段:
- Preprocessing
- 使用 SAM2 提取手和物体的 Mask,利用 MoGe-2 估算每一帧的深度信息和相机内参。
- 利用VLM引导出3D物体。
- Initialization of Pose and Scale
- 利用 WiLoR 模型预测手部的形状参数
,姿态参数 和全局旋转 。 - 尺度估算。确定全局物理尺度。
- 锚定 IOF。确定物体的 6D 位姿。
- 利用 WiLoR 模型预测手部的形状参数
- Hand-Object Interaction Optimization
- 手部轨迹精炼。固定旋转,仅仅通过关节重投影损失
来微调手部的平移。 - 交互感知追踪。再固定手部之后,优化物体的旋转和位移。
:让物体的3D轮廓与画面里的对齐。 :利用DINO特征匹配,即使物体被挡住,也能靠语义特征认出位置。 :物体稳定性约束。通过物体表面的 SDF(符号距离函数)计算权重,防止物体在手工滑动。
- 手部轨迹精炼。固定旋转,仅仅通过关节重投影损失
AGILE
https://d4wnnn.github.io/2026/04/19/Notion/AGILE/