PreciseCache
Paper:PreciseCache Precise Feature Caching for Efficient and High-fidelity Video Generation,ICLR 2026
解决的核心问题:DiT 加速。
前人不足:虽然此前有研究通过“特征缓存(Feature Caching)”来跳过某些去噪步骤的计算 ,但它们往往采用固定的均匀间隔或不够精准的触发指标 。这导致模型无法准确分辨哪些特征是真正冗余的,误跳过了重要特征的计算,从而造成视频生成质量的显著下降(如画面闪烁、变形等)。
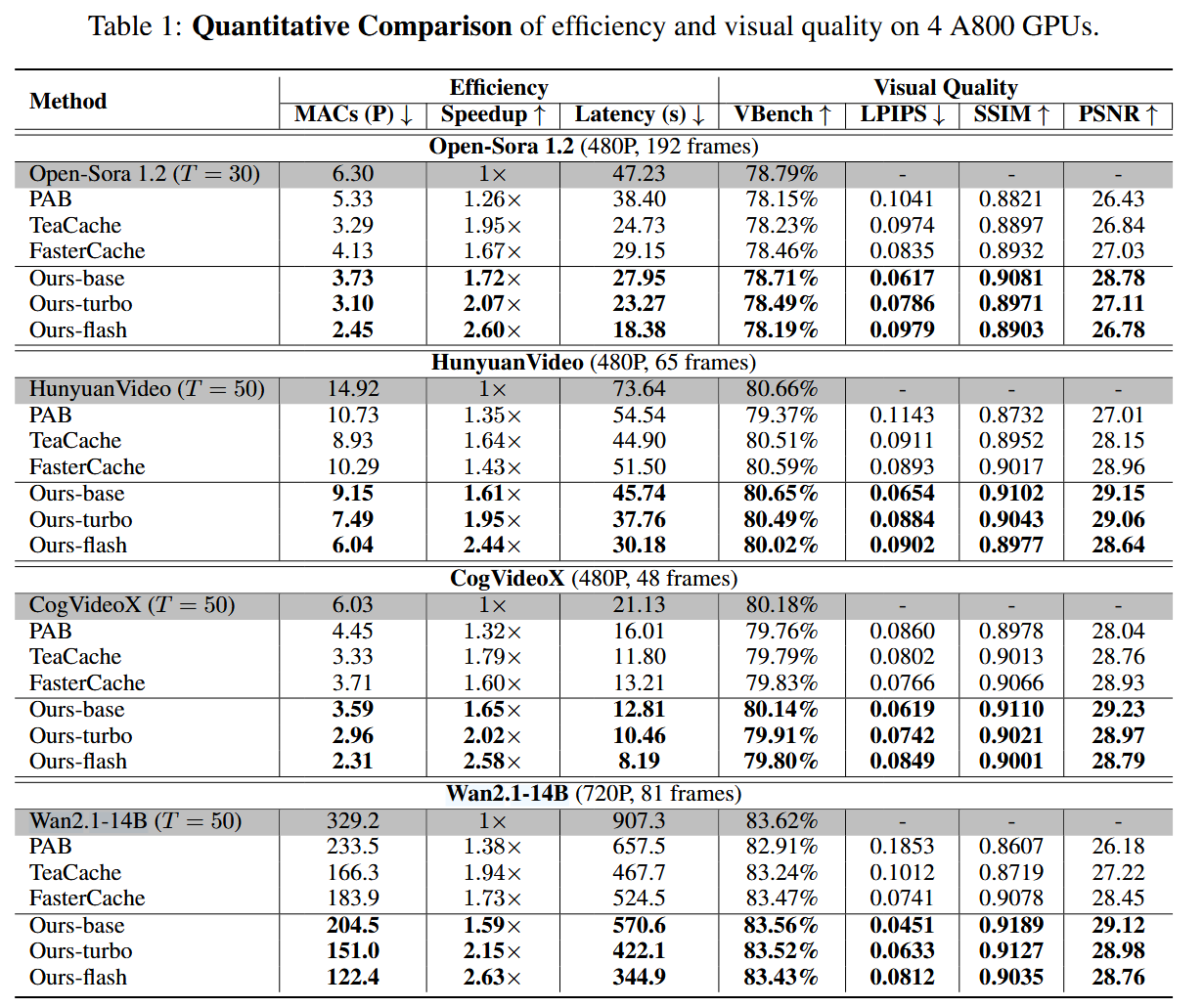
论文提出了一个名为 PreciseCache 的即插即用、无需训练的加速框架 。它从时间步级(Step-wise)和网络块级(Block-wise)两个空间粒度,精准检测并剔除真正冗余的计算。
核心方案
创新点一:时域自适应缓存 LFCache
在去噪过程中,高噪声阶段主要决定视频的“底层结构和轮廓”(低频信息,极其重要,不能跳过),而低噪声阶段只负责修饰“感知不明显的细节”(高频信息,可安全跳过)
利用快速傅里叶变换(FFT)提取模型预测特征
的低频分量 : 定义低频差异(Low-Frequency Difference, LFD)来衡量相邻时间步之间结构信息的改变程度:
在实际推理中,如果累加的低频误差
创新点二:网络块级别自适应缓存
也就是跳过一些 Block。
在前面的一些 Step,所有的 Block 都参与计算,然后计算一下哪些 Block 没啥用。
对于第
算出所有 Block 的差值后,对它们求
- 如果是核心块(在 Top
里面):保持正常计算,让特征老老实实地过一遍这个 Block。 - 如果是非核心块:
核心思想:那些在第
实验效果: