TRELLIS
Paper:Structured 3D Latents for Scalable and Versatile 3D Generation
论文解决的核心问题:现有 3D 生成模型有一个大麻烦:3D 表示形式太多,而且各有短板。
于是论文想生成一个统一的 3D latent representation,让同一个生成结果可以灵活解码成不同 3D 格式:SLAT,全称是 Structured LATent。
如何理解:
- 在一个稀疏 3D 网格上,只保留物体表面附近的有效 voxel;每个有效 voxel 上挂一个 latent vector,用来表示该局部区域的几何和外观细节。
论文的核心方法分成两个阶段。
阶段0:数据准备
首先用 Sparse Structure VAE 将一个已有的 3D 资产转换成
然后每个资产渲染 150 张各个角度的图,然后用 DINOv2 提取多视角的 feature map。再把每个 active voxel 投影到这些图上,聚合得到 voxel feature:
阶段1:生成稀疏结构
由于直接在
作用有两个:
- 降低成本
- 把离散的 0/1 voxel grid 变成连续的 latent,方便训练。
然后训练 Diffusion。
注入的条件支持文本和图片,通过 Cross-Attention 注入,时间步通过 AdaLN 注入。
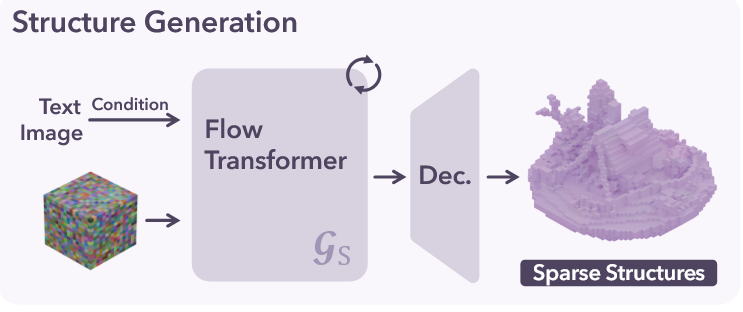
阶段2:生成局部 latent
然后论文同样训练一个 3D-VAE,只不过这次压缩的 Voxel 是贴色的。
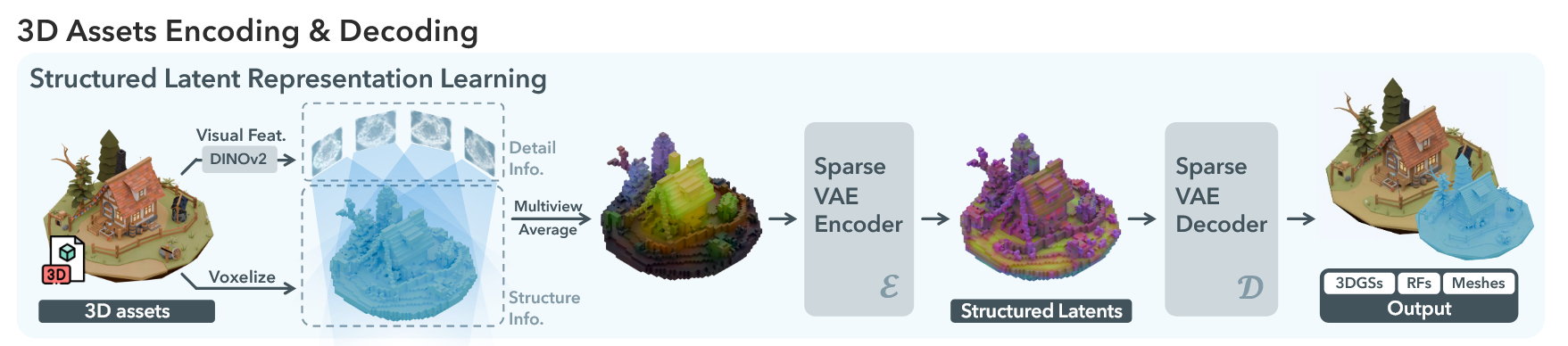
然后注入条件开始训练 Diffusion。
这里的条件有两种:
- 文本/图片。
- 真实的 Voxel(贴色)。
TRELLIS
https://d4wnnn.github.io/2026/05/26/Notion/TRELLIS/