TeaCache
Paper:Timestep Embedding Tells: It’s Time to Cache for Video Diffusion Model
要想知道模型输出变化大不大,常规做法必须把模型跑完才知道,但这在逻辑上陷入了死循环(为了省算力而不得不先耗费算力计算)。
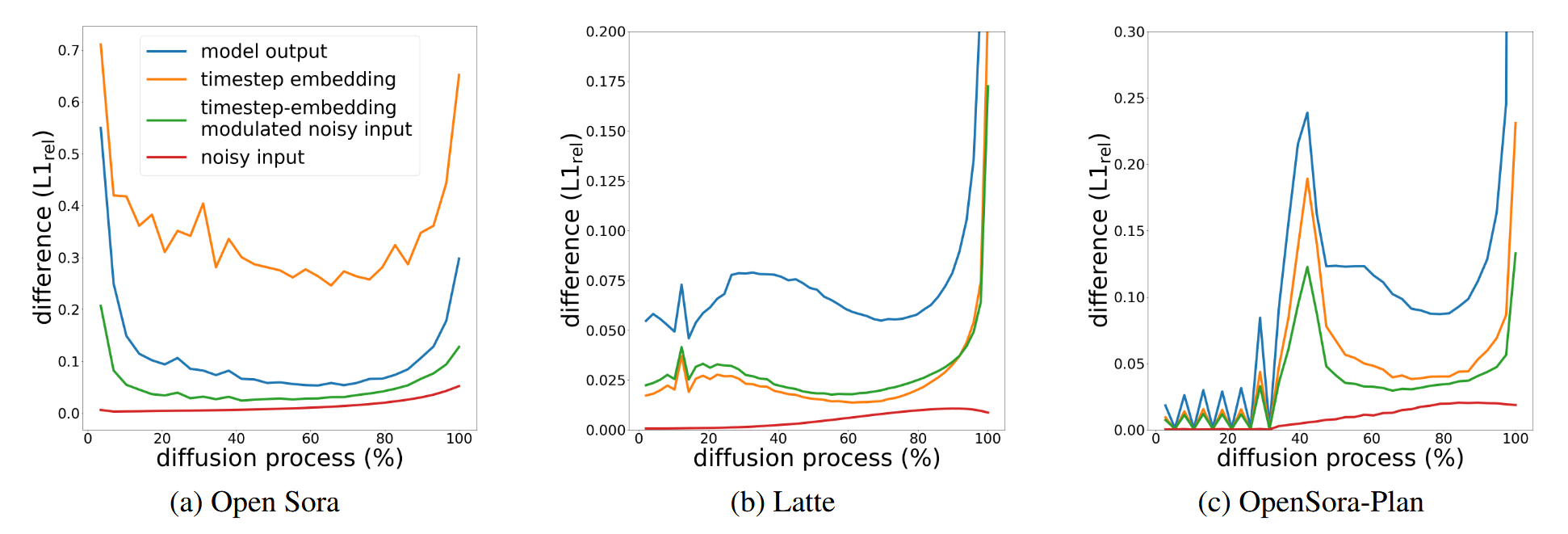
作者巧妙地将目光投向了模型输入 。经过对文本嵌入、噪声输入和时间步嵌入的消融分析,他们发现单独的噪声输入对时间步不敏感 ,而经过时间步嵌入调制后的噪声输入与最终的模型输出有着极强的正相关性 。
第一步:计算两个 Step 的输入特征差异
在第
第二步:用多项式把“输入差异”变成“模拟的输出差异”
作者发现这两个连续 Step 的输入差异和输出差异,曲线形状高度一致,但是数值上有一个固定的“缩放偏差” 。
为了纠正这个偏差,论文用了一个最基础的高中数学工具——多项式拟合
他们把第一步算出来的“输入差异”放进函数
现在 TeaCache 知道了“模拟的输出差异” 。它会把最近几步模拟出来的差异累加起来 。
- 如果累加的差异很小(低于阈值
): 直接利用缓存。 - 如果累加的差异很大(超过阈值
): 重新计算,更新缓存。
问题是这个多项式怎么获得?
在算法正式发布或部署前,作者在后台挑选了 70
个提示词(Prompts) 。对这 70
个提示词,作者确实老老实实、不做任何缓存地全量跑了一遍模型
。在这个过程中,他们记录下了每一时刻真实的输入差异
然后,利用 numpy.poly1d 这个极其基础的数学工具,把这 70
个视频产生的成千上万个