TrajectoryCrafter
Paper:TrajectoryCrafter: Redirecting Camera Trajectory for Monocular Videos via Diffusion Models,ICCV 2025 Oral
核心问题:如何从单目视频(普通单镜头拍摄的视频)中,精准控制并重定向相机的运动轨迹,生成高保真且时空连续的4D新视角视频。
核心创新点
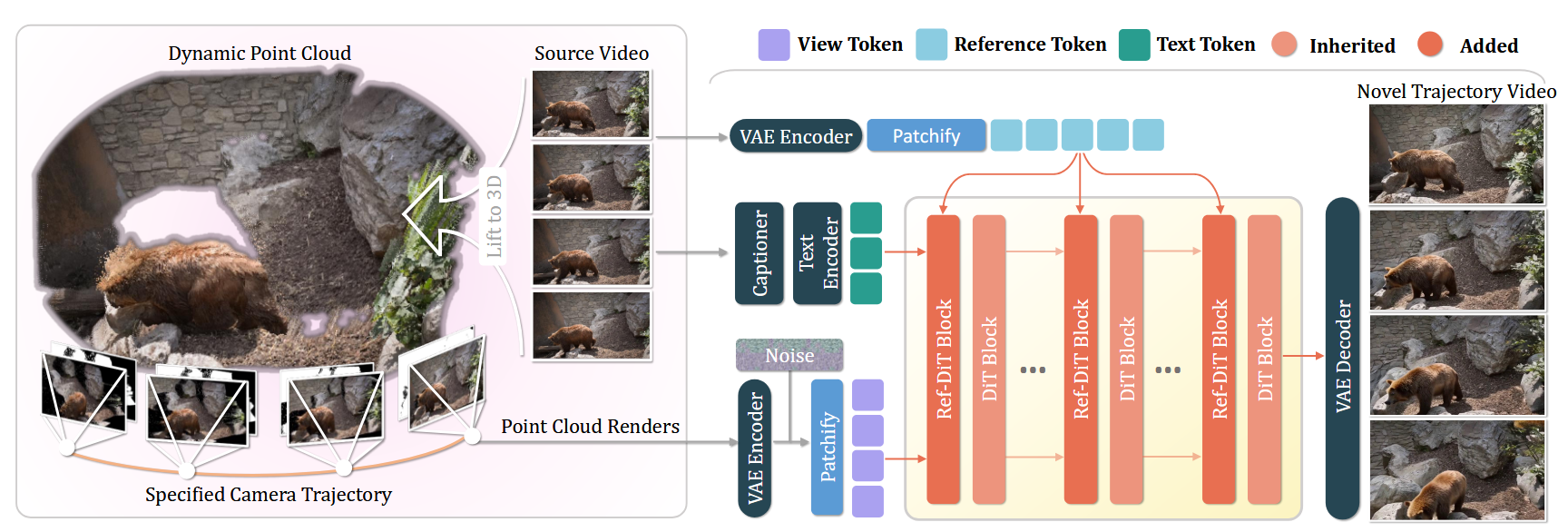
创新点一:解耦控制,用动态点云把“几何轨迹”定死
有点类似 Voyager。
单目提深度:先用单目深度估计模型(如 DepthCrafter)把输入视频
算出一套连续的深度图 。 升维成点云:利用逆透视投影公式,把 2D 视频画面“反推”到 3D 空间,变成动态点云
: (通俗理解:把平面的像素根据深度,在三维空间里摆成一个立体的点组成的模型 )。
渲染新视角:根据用户指定的任意相机轨迹
,把点云投影渲染回 2D,得到新视角的视频条件 : (通俗理解:直接在 3D 空间里移动虚拟摄像机去拍这个点云模型 。虽然因为遮挡会有很多黑洞、拉伸,但它的透视关系、运动轨迹是 100% 绝对精准的 )。
创新点二:Ref-DiT 架构
光有带洞的投影图
- View Stream(视角流):把带洞的新视角投影图
作为主输入(View Tokens),用来死死卡住相机的轨迹 。 - Reference
Stream(参考流):把高清的原视频
编码为参考特征(Reference Tokens) 。 - 交叉注意力融合(Cross-Attention):在 Ref-DiT 模块内部,以视角流为 Query,参考流为 Key 和 Value 进行注意力计算 。
创新点三:双重重投影策略
既然找不到那么多“动态多视角视频”来训练,怎么教会网络去补洞和迁移纹理呢?论文提出一个非常聪明的自监督套路 :
拿一段普通的单目视频
充当“答案” 。 将它升维成点云后,故意给它一个随机的视角变换,渲染成新视角
。 紧接着,再用相反的变换把它变回去,得到
。 这时候你会发现,
已经回到了原视频 的视角,但因为中间折腾了一圈,它身上多出了很多因为遮挡产生的空洞和伪影 。 训练任务达成:把带洞的
作为输入条件,让模型去复原成无损的 。这样,不需要多视角数据,只靠海量互联网单目视频就能让模型学会强大的“补洞”和“去畸变”能力 。