ViewCrafter
Paper:ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis,TPAMI 2025
论文解决的核心问题是:输入一张图和相应的轨迹,生成一个视频。
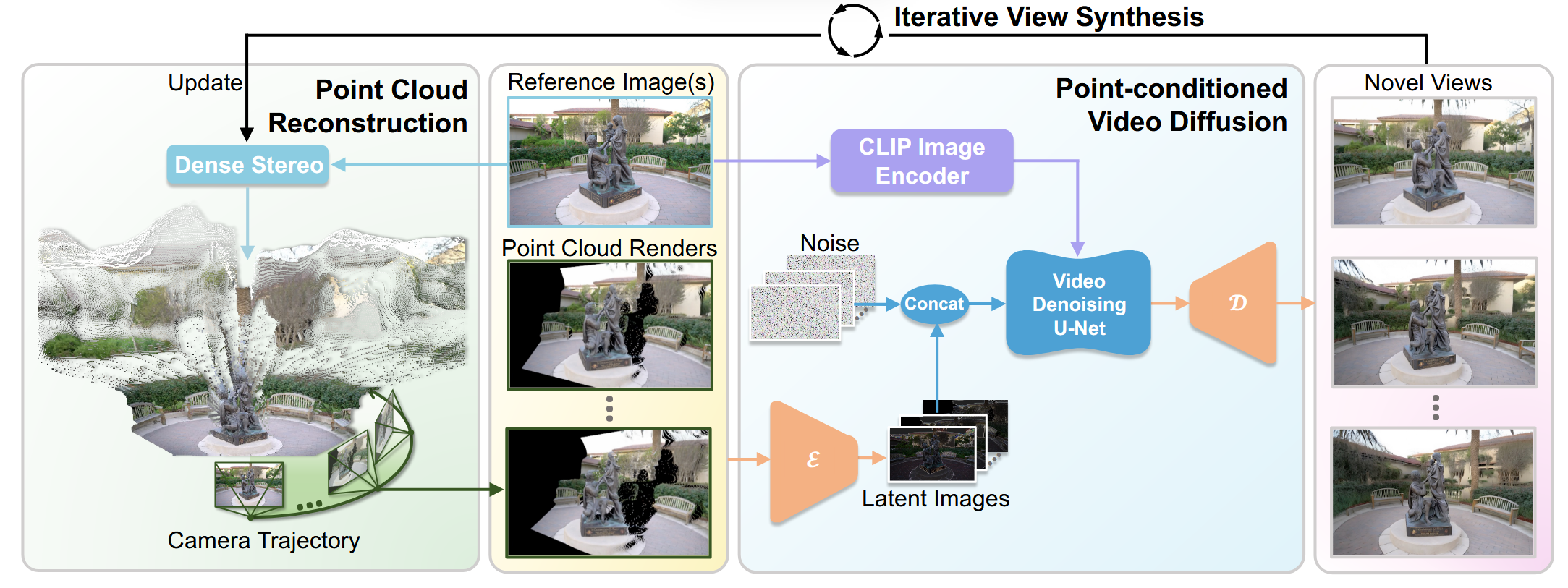
创新点1:点云条件视频扩散模型
同样是类似 Voyager 和 TrajectoryCrafter,根据单张图片和轨迹得到点云后投影成视频,作为结构条件约束模型。
创新点2:自适应相机轨迹规划与迭代视角合成
扩散模型生成长视频极度消耗显存且容易崩塌 。为了能看更多、更远的视角,论文设计了“走一步,看一步,补一步”的迭代策略 。
它没有使用死板的预设轨迹,而是提出了一个“下一步最佳视角(Next-Best-View)”的规划算法 。相机会自动去探测当前点云里哪里“缺失严重/有盲区”,就往哪里移动 。生成新视角的视频后,再把这些新画面反向投影回全局点云里,把原有的点云“越滚越大、越补越全” 。
相机如何挑下一步?
通俗拆解:
ViewCrafter
https://d4wnnn.github.io/2026/05/27/Notion/ViewCrafter/