HunyuanWorld 1.0
Paper:HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
目前已有的3D 世界模型生成方案主要存在两大痛点 :
- 基于视频的生成(Video-based):虽然视觉多样性丰富,但由于本质上是 2D 帧组合,缺乏真正的 3D 空间一致性,视角拉长就会产生严重的漂移,且渲染成本极高,无法直接导入游戏引擎 。
- 基于 3D 资产的生成(3D-based):虽然保证了显式的几何一致性,但高质量的 3D 场景数据集极度匮乏 。此外,过去的模型生成的 3D 场景多是“一块铁板”(Monolithic),物体之间相互粘连,无法进行单独的交互或操纵(如无法移开一辆车或一扇门) 。
论文思路是:将 2D 扩散模型的“高画质与多样性”和 3D
的“几何一致性”有机结合 。
其核心架构是一个分阶段的生成管线:文字/单图
核心创新点
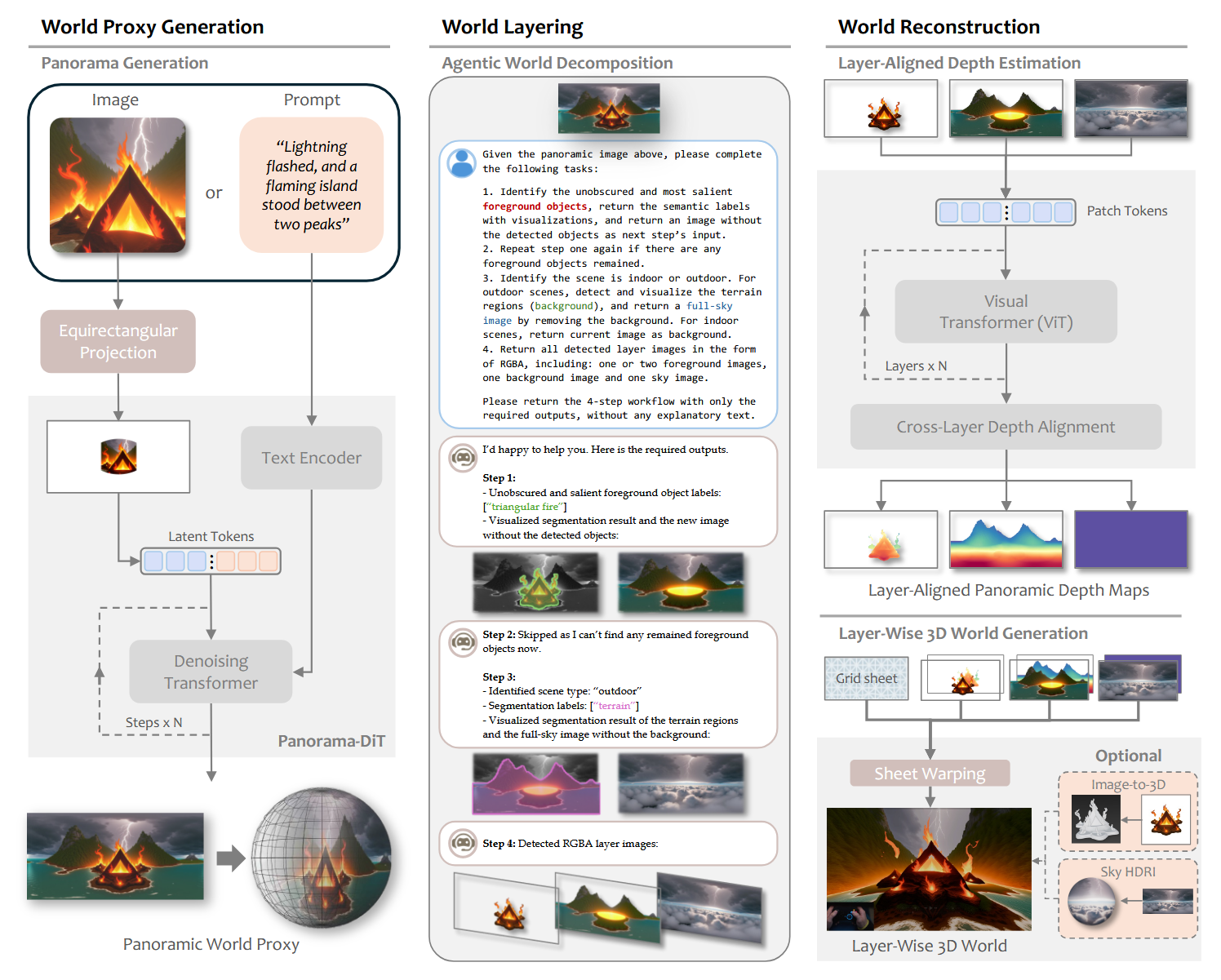
创新点 1:以全景图作为世界代理
- 用 Panorama-DiT将输入的文本或单张切片图,生成一张
的等距柱状投影(ERP)全景图作为物理世界的“代理” 。
创新点 2:智能体驱动的世界分层
- 利用多模态 LLM 去理解全景图里哪些是静态背景(如地面、山脉),哪些是需要交互的前景物体(如城堡、桌子、车辆) 。然后配合目标检测(Grounding DINO)和分割模型,把它们剥离成不同的 Layer:天空层、背景层、以及若干个独立的前景物体层 。
创新点 3:跨图层深度对齐重建
有了各个拆开的图层后,要将它们变回 3D。模型首先预测原始全景图的“基准深度图”(Base Depth Map) 。对于被抠出来的其他图层,单独预测其深度,并使用深度匹配技术(Depth Matching)进行对齐 。
虽然论文中主要以算法策略表述,但其核心的跨图层深度对齐,在数学本质上是通过最小化重叠区域的距离约束来完成的。设基准全景深度为
其他
什么是 Panorama-DiT?
全景图和普通照片不同,它具有严重的球面几何畸变,并且左右边界在物理空间上是首尾相连的。
为了适应这种特殊的图像格式,Panorama-DiT 核心引入了以下定制化的改进策略,这也是其最关键的创新点:
- 循环去噪:在 Transformer 计算图像边缘斑块的自注意力时,强行让最左边的 Patch 能够看到最右边的 Patch。这样模型在去噪生成时,就会天然地把左右两端当成连续的画面来画,从而实现无缝拼接。
- 视场/高度感知增强:为了让模型能够自如地应对不同摄像机拍摄角度、不同视角高度带来的全景畸变,在训练阶段,算法会将真实的 ground-truth 全景图在垂直方向上进行随机的位移和上下循环滚动(Vertical Shifting) 。这极大地增强了变压器对高度、仰角变化的鲁棒性,让生成的 3D 世界代理拥有更广阔、更逼真的天地纵深 。
HunyuanWorld 1.0
https://d4wnnn.github.io/2026/05/28/Notion/HunyuanWorld 1.0/