ControlNet
Paper:Adding Conditional Control to Text-to-Image Diffusion Models
核心就是可控生成。
核心模型
ControlNet 将预训练大模型的网络块参数完全冻结,从而完美保留大模型从数十亿张图片中学到的鲁棒生成能力 。同时,它完整复制一份这些编码层的结构作为可训练副本,专门用来学习特定的空间控制条件(如 Canny 边缘、人体骨架等) 。
论文的核心创新点是零卷积连接。训练刚开始时,可训练副本生成的特征是随机的、带有噪声的,如果直接加回原网络,会瞬间破坏原模型的 hidden states 。于是作者引入了零卷积,定义如下:
- 第一步:
输入控制条件 (比如线条图),经过第一层零卷积 。因为零卷积里所有的参数都是 0,任何数乘以 0 都等于 0。所以这一步的结果是 0。 - 第二步:
进入可训练的副本网络 。此时它接收到的输入就是原本的特征 (因为加上了 0)。这时候副本网络会计算出一个结果,但因为刚开始训练,这个结果其实是没意义的随机噪声。 - 第三步:
这个带噪声的结果在输送回主网络之前,必须通过第二层零卷积 。由于这层卷积的参数也是 0,噪声乘以 0,再次变成了 0!
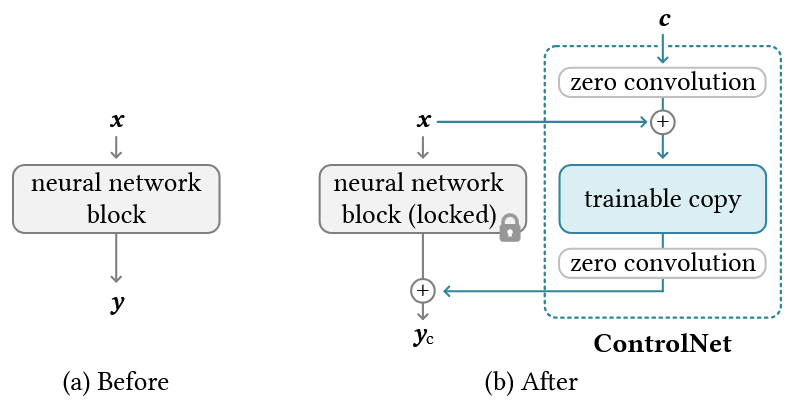
梯度传到零卷积这一层时,会开始强制更新它的权重,让它慢慢变成非 0 的微小数字
训练细节
由于零卷积的保护,模型在训练前几千步时,虽然图片质量很高,但似乎“不听指挥” ;然而在大约不到 10K 步的某个临界点,模型会突然学会顺从输入的控制条件 。作者称之为“突然收敛现象” 。这种微调策略既鲁棒又高效(甚至可以在单张消费级显卡 RTX 3090Ti 上完成微调)
在实际训练过程中,作者采用了这样一个小技巧:随机将 50%
的文本提示词
如果每张图都配有完美的文字描述,ControlNet
就会偷懒,去依赖文字而不是去认真学习空间控制图像
融合细节
- 复制前半段: 控制网络其实只复制了主网络的编码器(12个块)和中间块(1个块),它没有解码器 。
- 内部拦截与注入:
控制网络拿着“图像+文本+控制条件”,在自己的 12 个编码块里走一遍,提取出
12 个带有控制线条指南的特征图 。
- 这 12 个特征图各自经过一层零卷积(抹杀初始噪声) 。
- 直接注入: 注入到哪里呢?直接加到主网络 U-Net 对应的 12 个跳跃连接和中间块上。
ControlNet
https://d4wnnn.github.io/2026/05/29/Notion/ControlNet/