DMD
Paper:One-Step Diffusion with Distribution Matching Distillation,CVPR 2024
传统的扩散模型虽然生成图像质量极高,但其核心痛点是慢 。它们必须通过一个漫长、迭代的去噪过程才能将高斯噪声转化为图像 。这极大地限制了其在实时交互、设计预览等高时效性场景中的应用 。
虽然此前也有许多“蒸馏”方法(想把多步压缩到单步),但它们要么生成质量塌方,要么在蒸馏训练时需要完整跑完多步去噪轨迹,导致计算成本极其高昂 。
DMD 解决的核心问题就是:如何在几乎不损失图像质量、不增加荒谬训练成本的前提下,把多步扩散模型“脱胎换骨”成一个只需要单步前向传播的极速生成器 。(最终实现 512x512 分辨率下 20 FPS 的实时生成 )。
如何解决
核心思想:不强求“单步生成器”去精确模仿原模型每一步的降噪映射轨迹,而是强求它们生成的“图像分布”在统计上和原模型一模一样 。
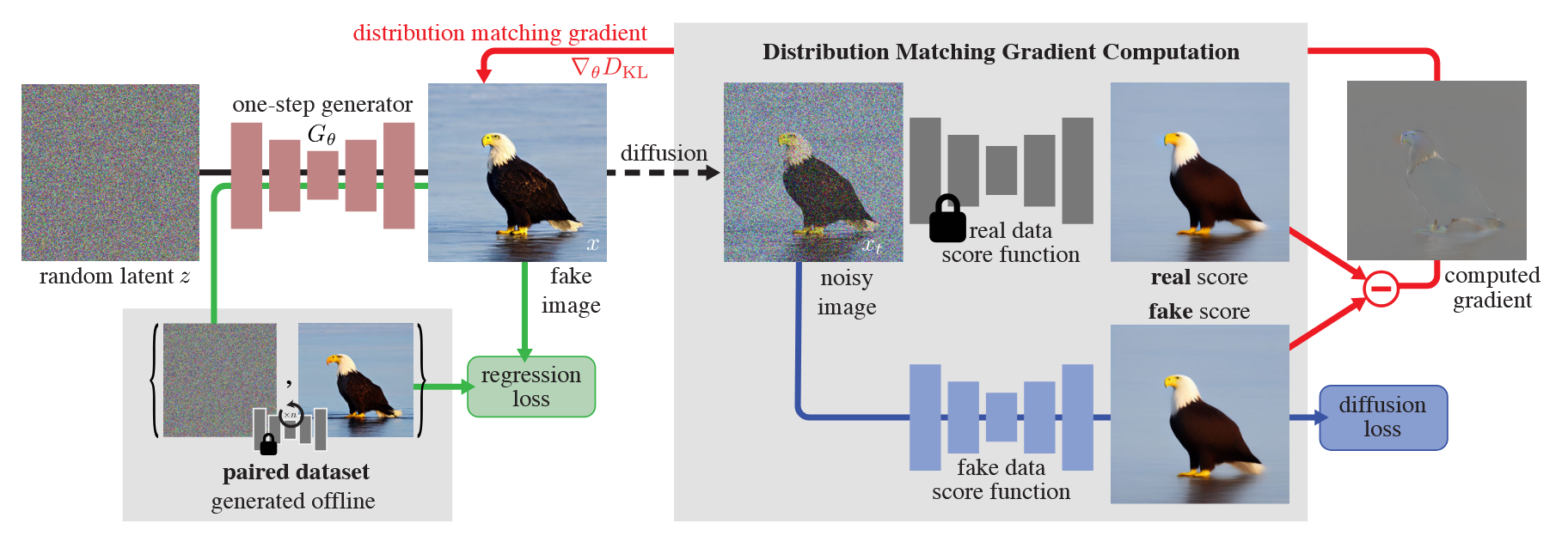
对于 student diffusion,最终 loss 可以分成两部分:
首先是 distribution matching loss,构造梯度:
其中:
:告诉 student 怎么像 teacher 的分布。 :告诉 student 怎么更像当前 fake 的输入。
然后是 regression loss。作者预先生成一些配对数据:
其中
这里的
DMD
https://d4wnnn.github.io/2026/05/30/Notion/DMD/