WAN
Paper:Wan: Open and Advanced Large-Scale Video Generative Models
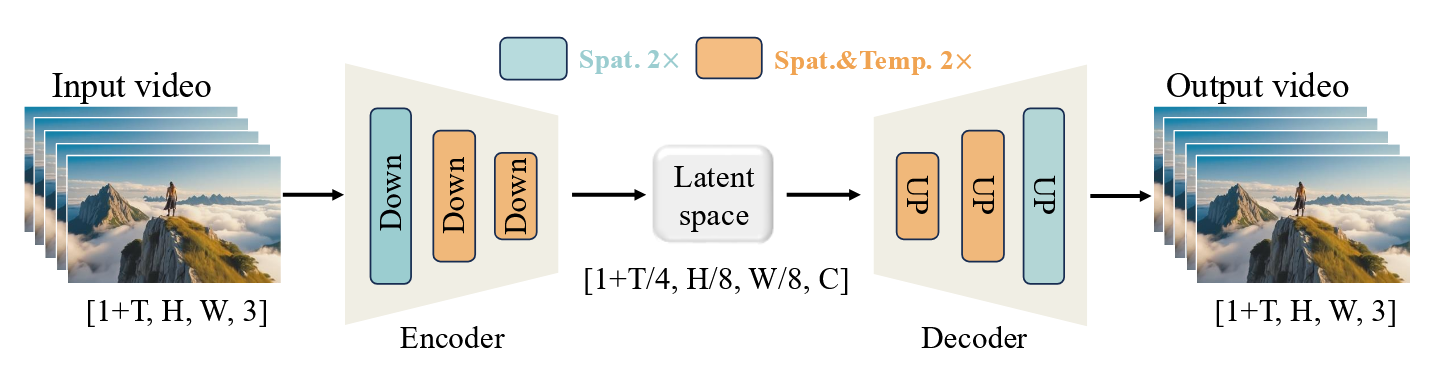
学习模块1:Wan-VAE
创新点1:发现 GroupNorm 会破坏因果性,并改良。
论文设计了一个具有 1.27 M 参数的 casual 3D
VAE,成功的将视频的时空维度压缩了
论文用 RMSNorm 替换了 GroupNorm,原因是 GroupNorm 可能会以来未来帧的统计量,破坏因果结构。
那么 GroupNorm 是如何计算的呢?
假设视频 latent 是:
如果用 GroupNorm(num_groups=4, num_channels=16),它会把
16 个 channel 分成 4 组:
1 | |
然后 对每个 batch 内、每个 group
内的所有元素计算均值和方差。也就是对这些维度一起算统计量:C_group × T × H × W
然后:
1 | |
但是 RMSNorm 只在 channel 维度 C 上计算 RMS。
创新点2:分块策略与特征缓存机制
传统的 3D 卷积在处理视频时,卷积核不仅在空间(H,
W)上滑动,还在时间轴(T)上滑动。假设你的视频有 100
帧,直接塞进一个普通的 3D 卷积层,这个卷积层需要同时将这 100
帧的特征图全部缓存在 GPU
显存中,用来计算时间维度的上下文。随着帧数
论文中整个视频被切分成由
论文默认复用前一个 Chunk 的最后 2 帧特征。
对于默认因果卷积:
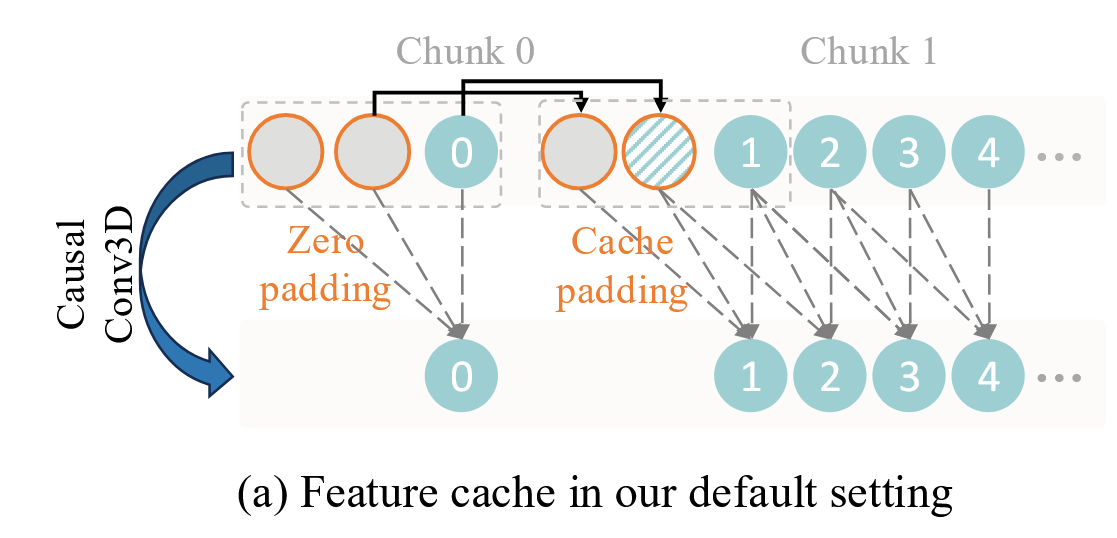
Kernal Size 通常是 3,为了计算当前块,它必须向前索要 2 帧 缓存,输出刚好等于 Chunk 的原始帧数。
对于时间下采样卷积层:
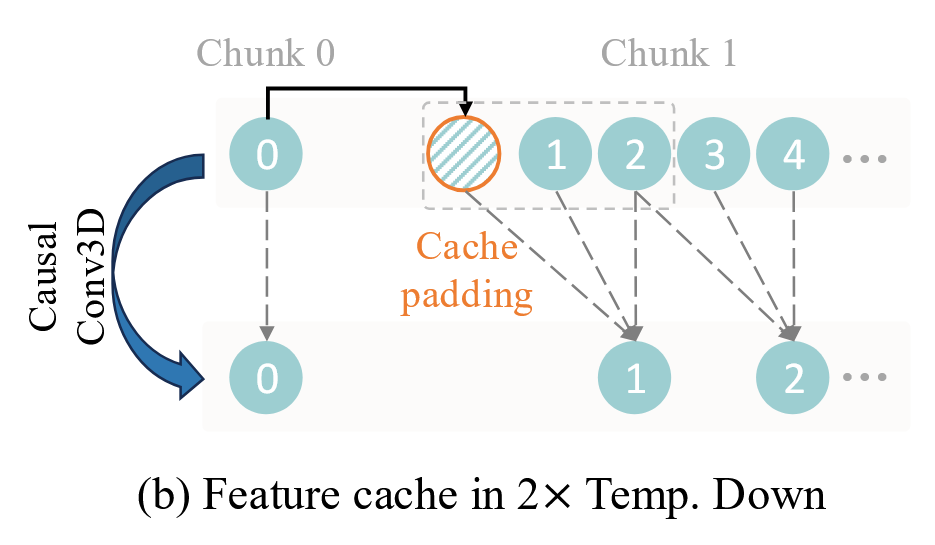
这类层负责将时间轴的分辨率压缩,它向前面索要 1 帧 缓存 。
学习模块2:DiT 架构的参数瘦身与能效优化
标准 DiT 是如何处理时间步
通常引入自适应层归一化:
其中,
系统框架:
1 | |
然后每一层都需要有两组参数,设模型的隐层维度为
然后 WAN 做了优化:
- 权重全共享:全局共同复用同一个全局投影矩阵的权重。
- 保留层独立偏置:让每一个 Block 学习一套自己独享的、非常轻量化的偏置向量。
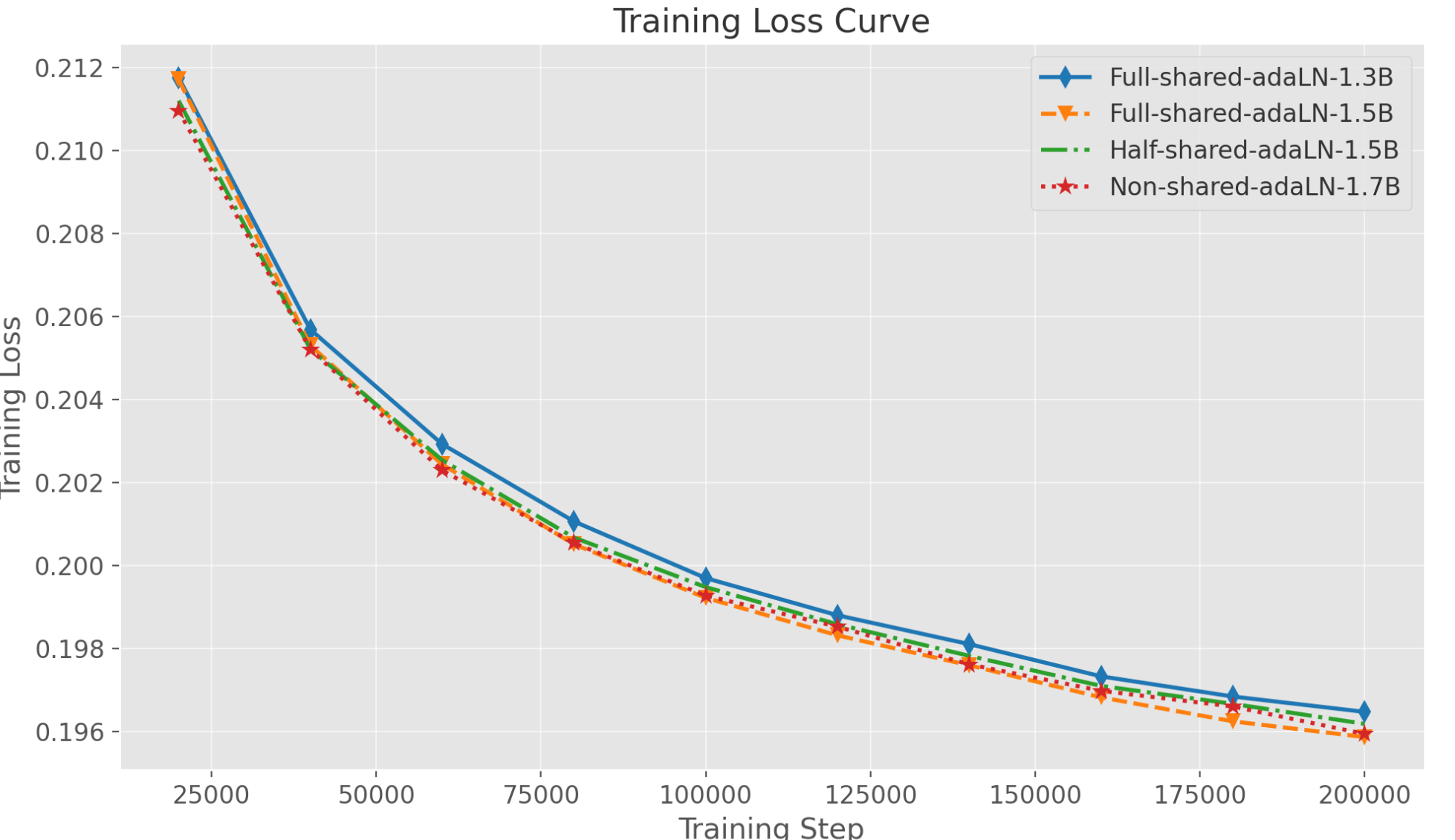
论文做了实验:
- Full-shared-adaLN-1.3B(基础款): 30层网络,参数全共享(Wan 的标准做法) 。
- Half-shared-adaLN-1.5B(半独立): 前 15 层共享,后 15 层保持独立不共享。由于增加了不共享的投影层,参数量膨胀了 0.2B,达到 1.5B 。
- Full-shared-adaLN-1.5B (extended)(加深款): 保持参数全共享,但利用省下来的参数预算,把网络层数从 30 层硬生生堆到了 35 层,此时总参数量同样对齐到 1.5B 。
- Non-shared-AdaLN-1.7B(完全不共享): 维持 30 层网络,但每一层都完全独立,不共享任何参数,总参数量高达 1.7B 。
发现:
- 同等参数量对比: 在相同 1.5B 参数规模下,加深款(35层+全共享)的训练 Loss 显著、持续低于半独立的 1.5B 模型 。
- 跨越参数量对比: 更加令人惊叹的是,即便是那个拥有独立参数、总规模高达 1.7B 的庞大模型,其最终的收敛效果也干不过只有 1.5B、但网络更深的加深款模型 。
结论:在 DiT 架构中,将参数堆在条件调制层(adaLN)的容量上是一种低效的浪费;将参数彻底解放出来,用来堆网络的深度(Depth,更多的 Transformer 块),才能带来最强的语义收敛和画质爆发 。
学习模块3:流匹配框架下的“图-影联合”多阶段预训练
Pre-Training
- 阶段1:纯图像的预训练
- 使用 256 像素的文本图像对从头预训练,没有任何视频。
- 阶段2:图像-视频联合训练
- 将训练数据切换为 256 像素的图像与 192 像素、5秒长度(16帧每秒,共80帧物理帧)的短视频剪辑 混合在一起进行联合训练。
- 阶段3:抬升分辨率
- 将图像和视频的分辨率统一提升到 480p。
- 但是视频的物理时常依旧是 5 秒
- 阶段4:继续提升分辨率
- 将空间分辨率推到最终的 720p 级别
- 视频的物理时常依旧是 5 秒
Post-Training
- 阶段5:模型维持 480p 和 720p 的高分辨率,但把数据源切换成了经过极致筛选的“高质量画质美感图”以及“具备复杂/简单运动且类目平衡的黄金视频” 。
其他
什么是 Plücker coordinates(普吕克坐标)?
是一种表示 3D 空间中“直线”的方式。在相机运动控制里,它通常用来表示:相机中心出发、穿过图像某个像素点的一条 3D 射线。
一条 3D 直线可以用两个三维向量表示:
其中:
所以 Plücker coordinates 通常是 6 维向量:
这也是为什么 Wan 论文里会写 camera condition 是:
意思是:对视频中每一帧、每个像素,都生成一个 6 维 Plücker 表示。Wan 在相机运动控制模块中用它把相机内参、外参转换成稠密的几何条件,再注入到 DiT 里控制镜头运动。