Hunyuan Video
Paper:HunyuanVideo: A Systematic Framework For Large Video Generative Models
创新点1:可直接外推的统一全注意力架构
传统的视频 diffusion 模型喜欢把时间和空间注意力拆开。而混元视频采用了统一的全注意力机制,把图像看作是“只有 1 帧的视频”联合训练 。
为了让模型能同时处理各种分辨率、宽高比和时长的视频,模型在每个 Transformer 模块中引入了 3D RoPE。
它将特征通道分给时间(T)、高(H)、宽(W)三个维度,分别计算旋转频率:
创新点二:混合流 DiT 骨干设计
文本和视频属于两种完全不同的语言,一上来就强行融合会让模型“精神分裂” 。
模型前半段使用 双流 (Dual-stream) 模块,让文本 token 和视频 token 在各自的通道里独立进化,互不干扰地学习自己的特征调制 ;后半段使用 单流 (Single-stream) 模块,将两者的 token 拼接在一起,进行深度的多模态信息融合 。
在总共
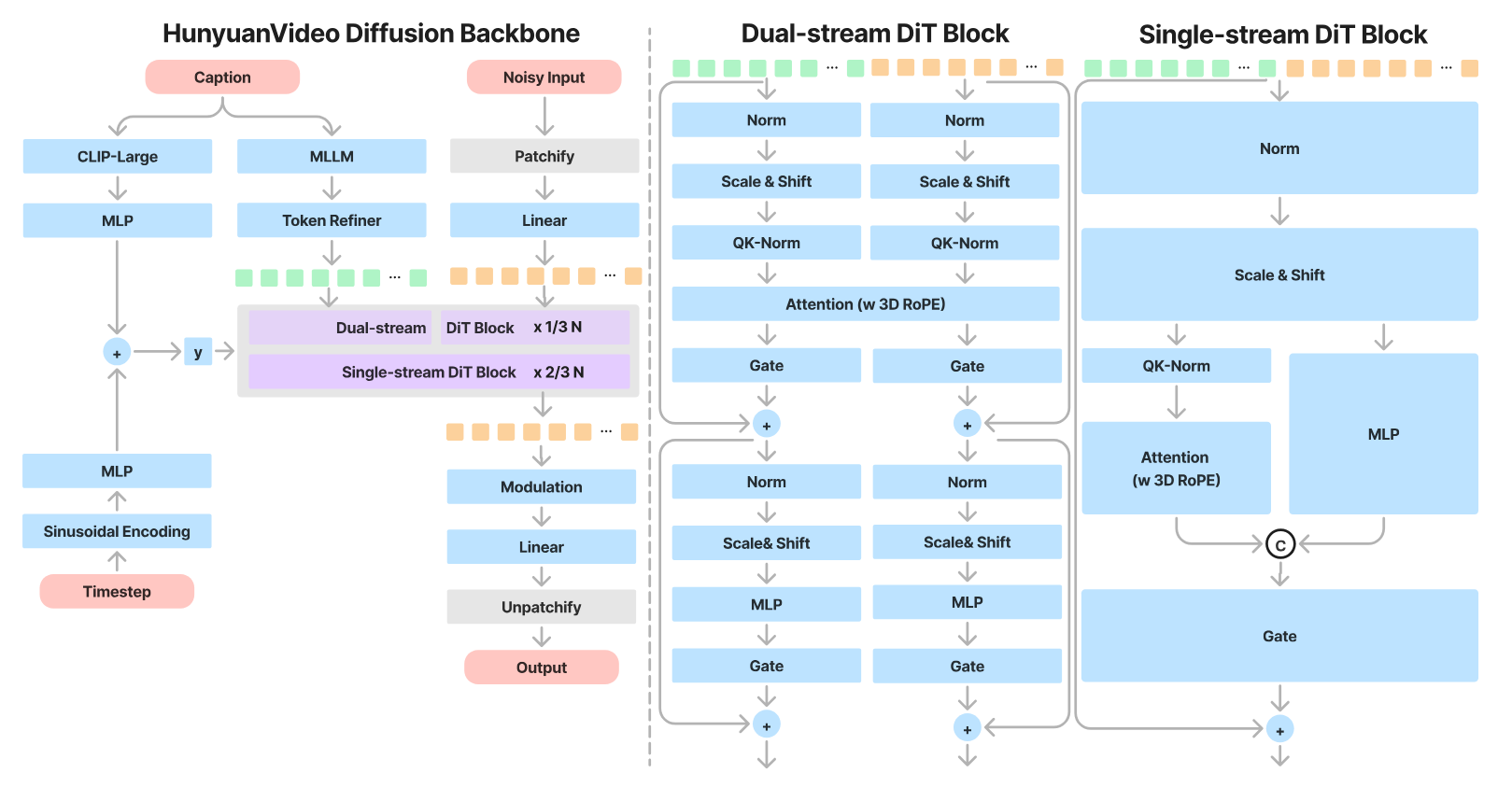
创新点3:MLLM 作为文本编码器
以前的文生视频(如 SD 系列)喜欢用 T5 或 CLIP 纯文本模型 ,但它们对图像细节的理解很弱。
混元直接采用经过视觉微调的 多模态 LLM (Decoder-Only 架构) 作为文本编码器 。MLLM 天生具有强大的图文对齐和复杂推理能力 。
因为 MLLM 是因果注意力(Causal Attention) ,为了弥补它在全局文本理解上的不足,论文在后面额外接了一个双向 Token 精炼器 (Bidirectional Token Refiner) 来增强文本特征的全局指导性 。
创新点四:首个扩散模型特定的时空缩放定律
大模型不能盲目烧钱去试参数。论文率先探索了基于 Flow Matching(流匹配)和均方误差(MSE)损失的视频大模型缩放规律 。
通过拟合幂律公式来决定最优模型大小
其中,计算量
论文首先推导文本生图模型(T2X-I)的 Scaling Law,设计了从 92M(9200万)到 6.6B(66亿)共 7 个不同参数量的模型。不同大小的模型在不同的算力区间会分别胜出(达到最低 Loss)。把这些所有曲线的最底端连接起来,就得到了一条灰色的性能包络线 。
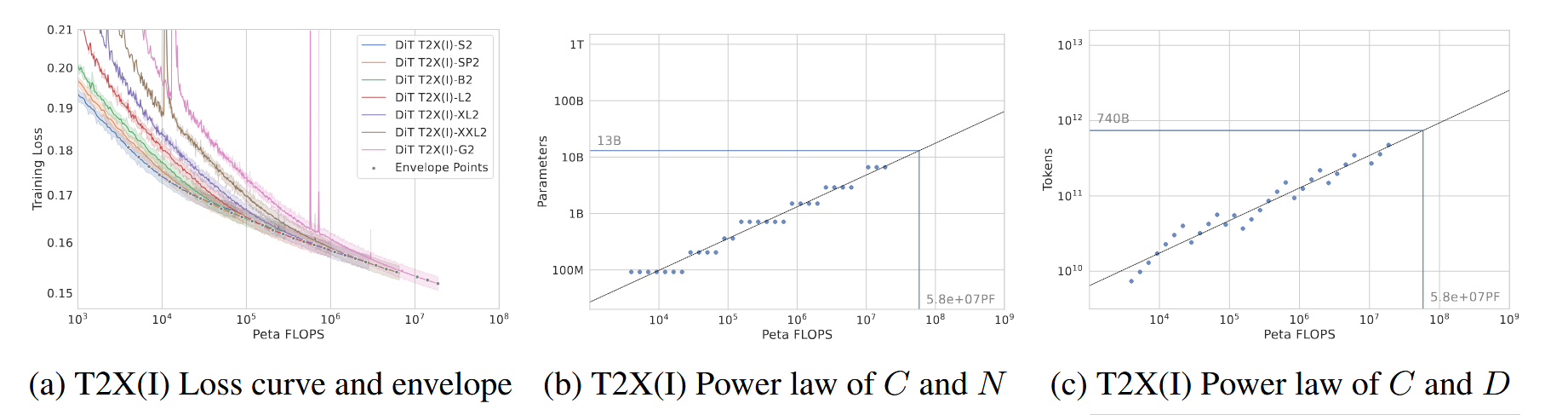
通过包络线上的数据点,他们成功拟合出了图像模型的系数:
有了图像模型的包络线后,他们做出了一个关键的科研假设:图像模型训练的最优点,就是视频模型训练的最佳起点 。他们从图像训练的包络线上,挑出各个规模处于最优状态的图像模型 Checkpoint,作为对应视频模型(T2X-V)的参数初始化 。 接着在视频数据集上继续训练,重复上述“跑 Loss、连包络线、拟合公式”的过程 。
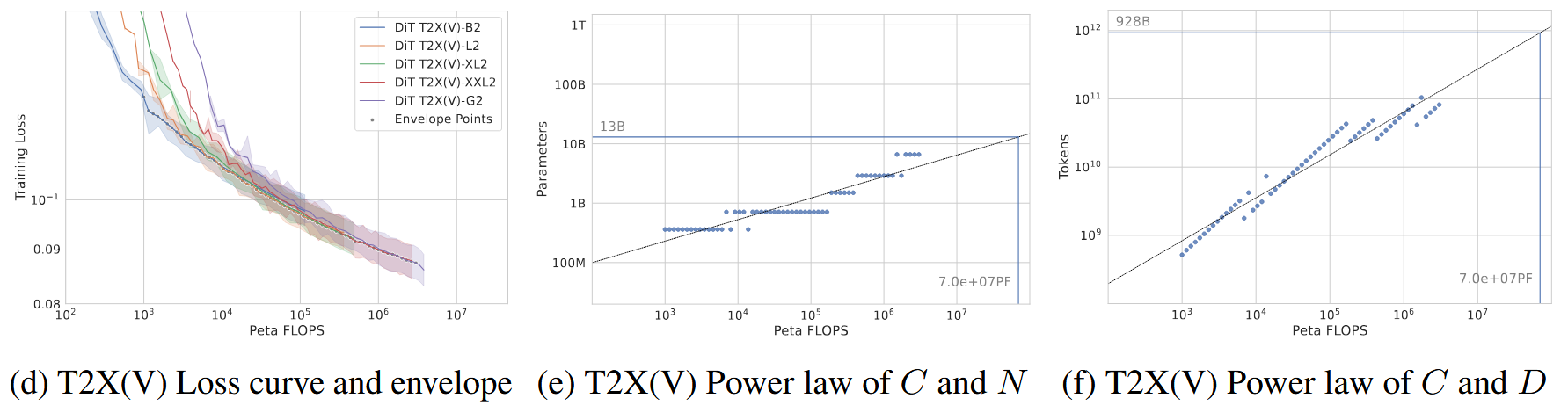
最终拟合出视频特定的 Scaling Law 系数 :
注意视频模型的两个指数 :模型大小指数
在传统的语言模型(大语言模型 LLM)中,这两个指数通常非常接近(都在 0.5
左右),这意味着算力每翻一倍,模型参数和训练数据应该各增加大约
40%(即著名的 Chinchilla 1:1 黄金法则)。
但在混元的视频 Scaling Law 中,情况发生了变化:
- 在视频生成任务中,模型的性能提升对“数据量(Token量)”的增加更加敏感,而对“模型参数量”盲目扩大的敏感度相对较低。
最终综合权衡了训练能耗、单卡显存以及推理延迟后,使用 13 B 的参数。
创新点五:高精度 3D 变分自编码器
不依赖任何预训练 Image VAE,直接从头训练了一个因果 3D Casual VAE,将视频和图像混合输入 。
联合了
三阶段渐进式训练 VAE:
- 第一阶段(Image
Pre-training):先不加时间轴,用纯图像在
分辨率下训练,让 VAE 快速学会怎么压缩和还原空间结构(线条、颜色)。 - 第二阶段(Video Joint
Training):加入时间维度,使用
分辨率、但包含多帧的视频片段,与图像混合训练,让模型学会沿时间轴的“因果压缩”,保证前后帧的连贯性。 - 第三阶段(High-Resolution Finetuning):最后,把分辨率提升到高保真的多尺度视频(比如 512px、768px),微调模型,全面捕获超清晰的细节。