Swin Transformer
Paper:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
传统的 Vision Transformer (如 ViT) 在作为通用视觉 Backbone 时,面临两大痛点 :
- 尺度不一致性:视觉实体(如目标检测中的物体)大小变化极大。ViT 的 Token 尺寸完全固定,难以适应需要多尺度特征的下游任务(如检测和分割) 。
- 高分辨率下的计算量爆炸:ViT 采用全局自注意力机制,其计算复杂度与图像的 Token 数量呈二次方关系。当面对高分辨率图像或需要像素级预测的任务时,计算开销巨大,甚至直接显存溢出 。
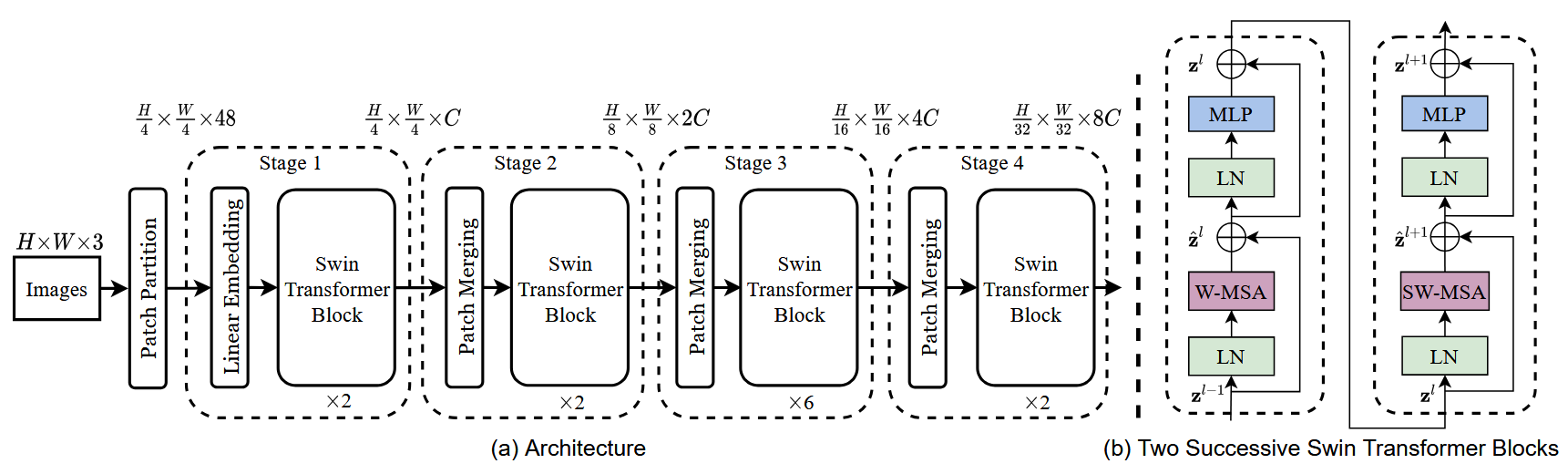
创新点一:构建层次化特征图—— 解决多尺度问题
设定初始 Patch 大小是
然后随着网络层数的加深,模型内部通过 Patch Merging,让特征图的尺寸(高、宽)成倍缩小,而每个 Token 的特征通道数(维度)成倍增加。
比如首先在空间上把相邻的
采样拼好后,维度太高了(
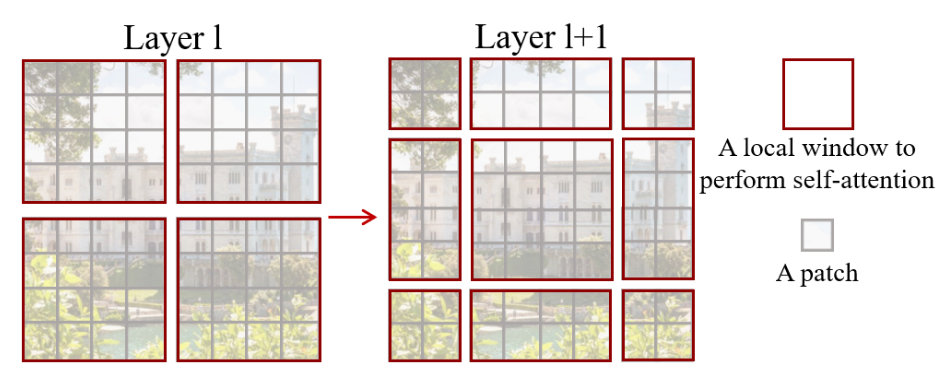
创新点二:基于移位窗口的自注意力
第一步:常规窗口自注意力
为了将计算量降下来,模型将图像均匀划分为不重叠的局部窗口(如每个窗口包含
第二步:移位窗口自注意力
只用 W-MSA 会导致一个致命缺陷:各个窗口各玩各的,彼此之间没有任何信息交流,这严重限制了模型的全局建模能力 。因此,在连续的 Transformer 块中,作者提出了移位窗口(Shifted Windows) :
- 做法:在第
层使用常规窗口划分,在接下来的第 层,将整个窗口划分向右下角平移 个像素 。 - 通俗理解:这就好比把之前的窗口边界打破了。新的窗口刚好横跨了上一层相邻的几个老窗口,让原本死生不相往来的邻居窗口在这一层能够进行信息融合 。
- 高效批处理优化:移位后会产生更多、更小的碎片窗口。作者没有采用 Padding ,而是创造性地使用了循环移位和掩码机制,把这些碎片拼成和原来一样大的标准窗口进行矩阵并行计算,既引入了跨窗口连接,又没有带来任何额外的计算延迟 。
Swin Transformer
https://d4wnnn.github.io/2026/06/02/Notion/Swin Transformer/