CogVideo
Paper:CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
传统的视频生成模型在面对复杂文本时,常常出现“生成的画面逐渐偏离 Prompt 的问题,导致视频中的角色无法准确执行指定的动作。
造成这一核心瓶颈的主要原因有两个:
- 数据极度匮乏与弱相关性:相比于轻松坐拥数十亿对的文生图数据集,高质量的文生视频数据集规模极小(如 VATEX 仅有约 4 万个视频),且互联网爬取的视频文本大多只描述场景,缺乏精准的时序动作信息 。
- 时空语义对齐困难(剪辑破坏动作完整性):过去的方法通常将长视频盲目裁剪为固定帧数的短片段进行训练,这直接切碎了原本完整的动作语义(例如:把一个完整的“喝水”动作切成了“拿杯子”、“举起”、“喝”、“放下”四个片段,但标签全叫“喝水”),导致模型在学习“文本-动作”对应关系时产生严重混淆 。
CogVideo的核心思路:直接继承并“冻结”已有的文生图模型(CogView2)的预训练权重,通过添加极少量的可训练时序模块来快速掌握视频生成能力 。
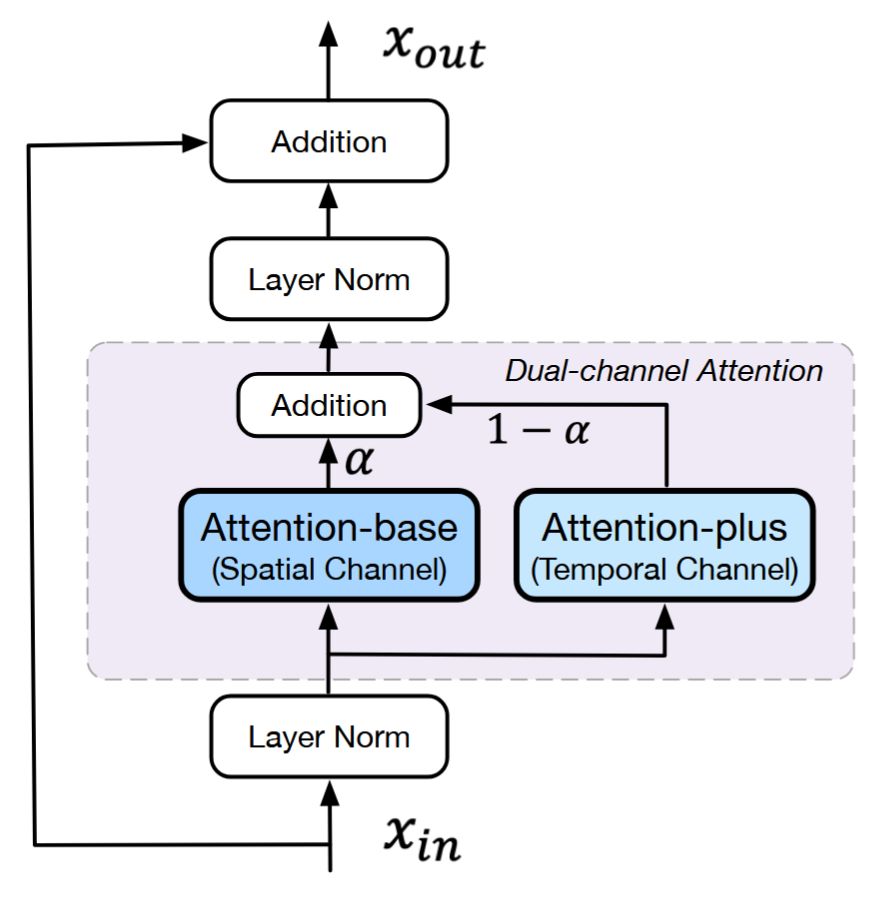
创新点 1:双通道注意力机制
原封不动地冻结图像模型的所有参数 ,然后在每一层 Transformer 里平行并联一个“时间通道” 。图像通道专门负责看空间构图,时间通道专门负责盯着帧与帧之间的前后运动,两者最后融合 。
公式定义如下:
其中
创新点 2:多帧率分层训练策略
作者在输入的文本前强行塞入一个“帧率Token”(如 1 fps、2 fps)。在训练时,对于一个长视频,模型会依据视频长度自适应选择最低的合适帧率去抽取 5 帧,确保这 5 帧能够跨越并覆盖一段“完整的动作语义”
模型每一轮训练只能吃固定的 5 帧图像(降低算力和显存开销),为了让这 5 帧尽可能完整地包含文本所描述的动作,作者设计了一套自适应最低帧率抽取算法 :
针对每一个视频,选择能满足抽取 5 帧的“最低预设帧率” 。
- 预设帧率池:假设系统里有预设的帧率池,比如
。 - 从低到高匹配:拿到一个视频后,先尝试最低的帧率(例如
,即每秒截取 1 帧)。 - 如果这个视频很长(比如有 6 秒),按
可以抽出来 6 帧。既然 帧,满足条件!那么就选定 ,并在前 5 秒各切一帧,凑齐 5 帧 。此时,这个训练样本开头的 Token 就是 [1 fps]。 - 如果这个视频很短(比如只有 1.5 秒),按
只能抽出来 1 帧,不够 5 帧 。算法就会向上升级帧率,尝试 (能抽 3 帧,还是不够) 再尝试 (每秒抽 4 帧,1.5 秒能抽 6 帧, 帧,满足!) 。此时,这组样本抽出的 5 帧之间时间间隔就很短,对应的开头 Token 就是 [4 fps]。
- 如果这个视频很长(比如有 6 秒),按
上面是训练的情况,然后推理的时候,这个 Token 需要由用户指定,然后后台程序递增。
然后第一轮生成 5 个关键帧。然后继续这5个关键帧作为条件输入到模型,然后这5个帧是双向注意力,然后生成的帧还是单向自回归。
创新点 3:三维自回归局部/自移窗注意力
视频序列极长,全全局自注意力计算会让显存爆炸 。作者把常用于非自回归任务的 Swin Attention 魔改成适合自回归的 3D 窗 。