BLIP
Paper:BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
现有的视觉-语言预训练(Vision-Language Pre-training, VLP)模型主要存在两大痛点:
- 模型层面(架构不统一): 现有模型要么采用基于编码器(Encoder-based)的架构(如 CLIP),擅长“理解型”任务(如图像-文本检索),但不易直接迁移到“生成型”任务;要么采用编码器-解码器(Encoder-Decoder)架构,擅长“生成型”任务(如图像描述),但在检索类任务上表现不佳 。
- 数据层面(网络噪音过大): 现有的性能提升极度依赖于从网络上爬取的超大规模图像-文本对 。但这些网络文本充斥着大量的噪音和错配,直接作为监督信号是次优的 。
核心方法
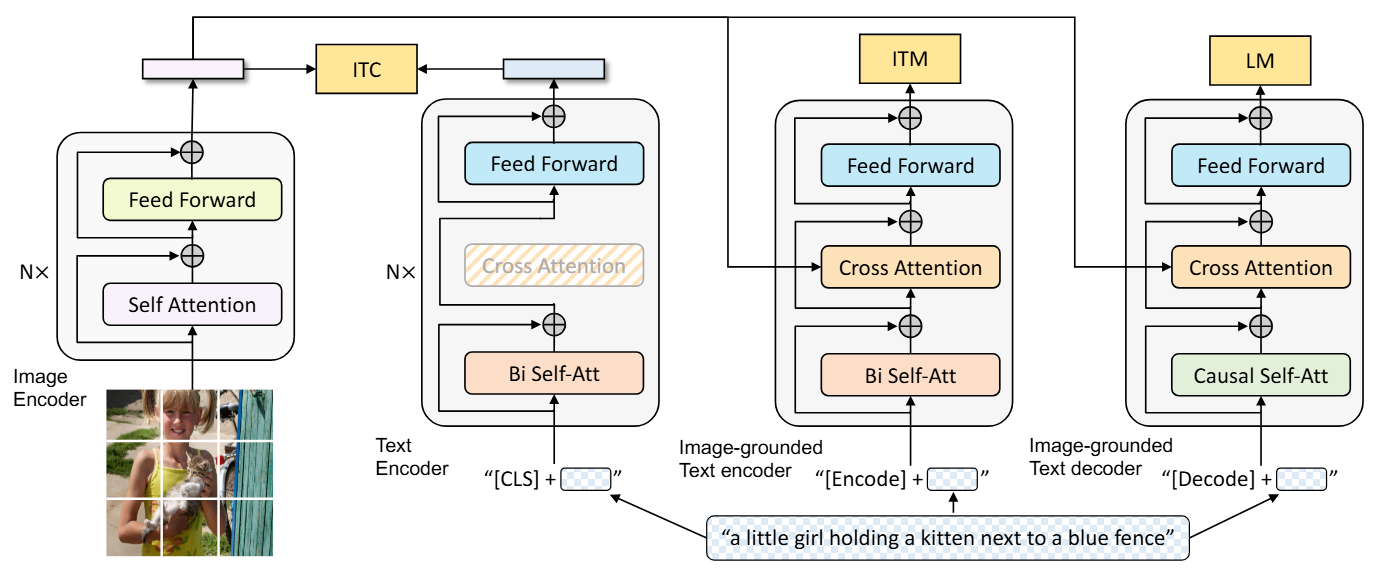
创新点1:多模态混合编码器-解码器 MED
为了用一套参数兼顾“理解”与“生成”,BLIP 设计了一个多功能、高度复用参数的全新架构 。它包含一个图像编码器(ViT)和一个文本 Transformer 。 这个文本 Transformer 通过共享大部分参数(除自注意力层外),可以像瑞士军刀一样灵活切换成三种模式 :
- 单模态 Encoder: 独立编码图像和文本 。文本输入前加
[CLS]标记 。- 预训练目标:图像-文本对比损失(ITC)。
- 图文融合 Encoder: 在文本 Transformer 的自注意力和
FFN 之间插入 Cross Attention 以注入视觉信息 。文本输入前加
[Encode]标记 。- 预训练目标:图像-文本匹配损失(ITM) 。
- 图文融合 Decoder: 将自注意力层替换为
Causal Self-Attention,用于预测下一个 Token
。文本输入前加
[Decode]标记 。- 预训练目标:自回归语言模型损失(LM)。
创新点二:图文数据集
先预训练一遍。
- 生成器: 对应 MED 的解码器模式,输入网络图片
,生成一个崭新的、更符合视觉内容的合成标签 。 - 过滤器: 对应 MED
的融合编码器模式,负责给原始网页文本
和合成文本 打分,如果 ITM 头预测它们与图片“不匹配”,就直接剔除 。
BLIP
https://d4wnnn.github.io/2026/06/02/Notion/BLIP/