BLIP2
Paper:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
论文要解决的核心痛点是:多模态预训练的计算成本过于高昂,且难以直接复用已有的顶级单模态模型 。
传统的视觉-语言模型通常采用“端到端”的训练方式,随着视觉模型和语言模型的参数量激增,从头联合训练两者的成本变得不可承受 。
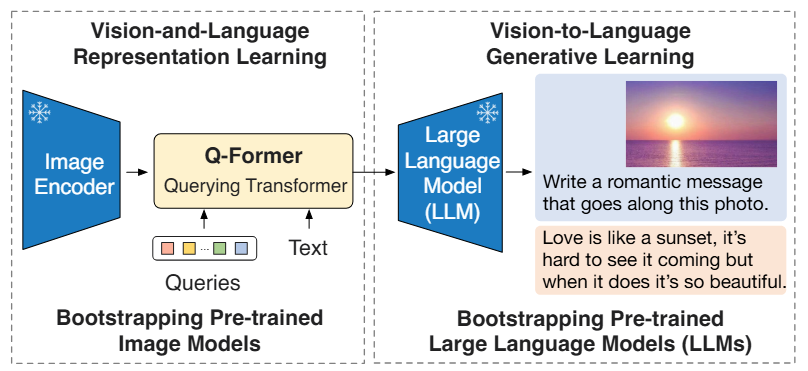
论文方案
BLIP-2 的核心创新是设计了一个轻量级的 Q-Former(Querying Transformer,仅 188M 参数) 作为“桥梁” 。它扮演了信息瓶颈(Information Bottleneck)的角色:一方面把庞大的视觉特征压缩成固定的与文本高度相关的符号;另一方面把这些符号转译成 LLM 能听懂的软提示(Soft Prompts)。
第一阶段:视觉-语言表征学习
在这个阶段,Q-Former 连接冻结的视觉编码器,利用一队可学习的查询向量(Learned Queries)去图像里“抽取”特征 。为了让抽取的特征带有语义,联合优化了三个经典的自监督目标 :
- ITC:图像-文本对比学习。
- ITM:图像-文本匹配。
- ITG:图像引导的文本生成 (Image-Grounded Text Generation)
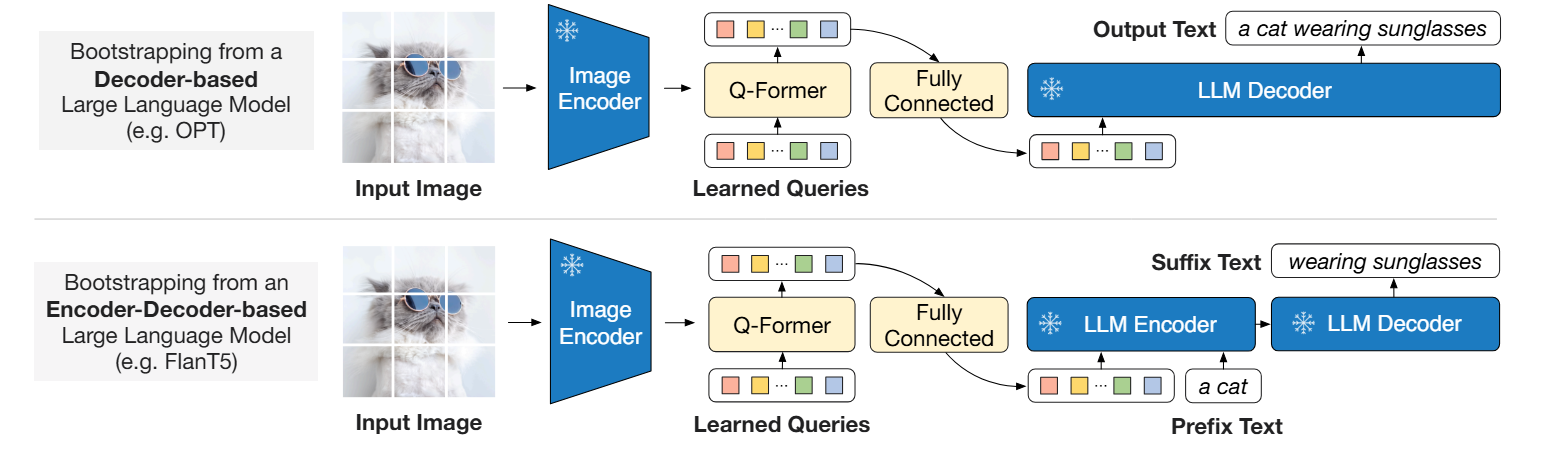
第二阶段:视觉到语言的生成学习
Q-Former 已经能提取出很好的视觉特征
- 如果对接的是纯解码器 LLM,使用标准的语言模型损失,让其预测后面的文本。
- 如果对接的是编码器-解码器 LLM,使用前缀语言模型损失(Prefix LM Loss),将视觉特征和文本前缀拼接喂给编码器,让解码器生成目标文本 。
问题
为什么不直接在第一阶段就用第二阶段的 LLM 文本编码器?
在第一阶段中,完全没有大语言模型(LLM)的参与。此时使用的文本编码器是Q-Former
内部自带的文本 Transformer 子模块。使用
大语言模型通常极其庞大 。如果在第一阶段做高频次的图文对比学习(ITC)和 hard negative 负采样匹配(ITM)时 ,每次前向传播都要带上一个几十 B 的 LLM,计算资源会瞬间枯竭。
为什么不直接用视觉编码器后加一个投影?非要对齐后再投影?
直接投影的问题:
- 假设视觉编码器输出的特征是
。如果直接投影喂给 LLM,意味着每张图片会变成 257 个视觉 Token 。对于大模型来说,上下文窗口极其宝贵。如果一个视觉标记里有 80% 都是无用的背景噪声,不仅浪费大模型的算力,还会干扰大模型的注意力。 - 视觉特征和 LLM 的词嵌入空间跨度太大。如果直接跨界投射,单靠一层线性层很难实现高维语义的平滑转换。为了让 LLM 听懂,你可能必须在第二阶段微调 LLM 本身的参数(或者训练一个非常重的对接网络)。但是,一旦你微调了数十亿参数的 LLM,它原本强大的纯文本生成能力和逻辑推理能力就会受损,也就是发生“灾难性遗忘” 。