DeepCache
Paper:DeepCache: Accelerating Diffusion Models for Free
论文发现,在用 Diffusion 去噪的时候,U-Net 内部的上采样块,在去噪的连续两步中,输出的特征图在肉眼上几乎完全一样。

a:不同的 Prompt 对应的不同步的特征图。
论文里是用上采样的倒数第二个Block的输出特征。作者对每个 Token 取绝对值的平均值 (或者 PCA压缩成一个通道),然后映射到彩色空间。
b:热力图,横纵坐标为时间步。作者将特征图展成一维,然后两两计算余弦相似度。
c:折线图,不同的模型在不同的数据集上,与当前步相似度大于0.95的临近步骤的比例。
也就是论文的核心发现:U-Net 内部的高层语义特征变化非常缓慢,具有极高的相似度
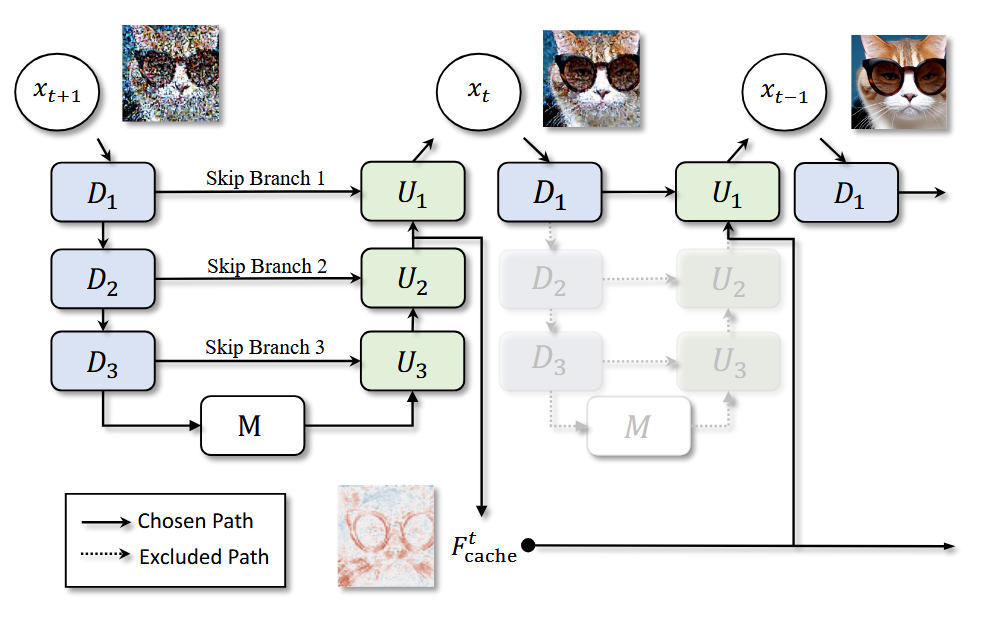
因此,论文在全量计算某个step后,会缓存高层的输出特征。然后在接下来的几步,只计算对应的浅层网络(更新低层细节)。
如果生硬地每隔
为了解决这个问题,作者提出了非均匀空间采样
。通过引入中心点
首先生成二次方级分布的初始序列:
其中,
比如:
然后映射回真实的时间步
也就是把
最终选出来的真实全量推理时间步集合为: