PPO
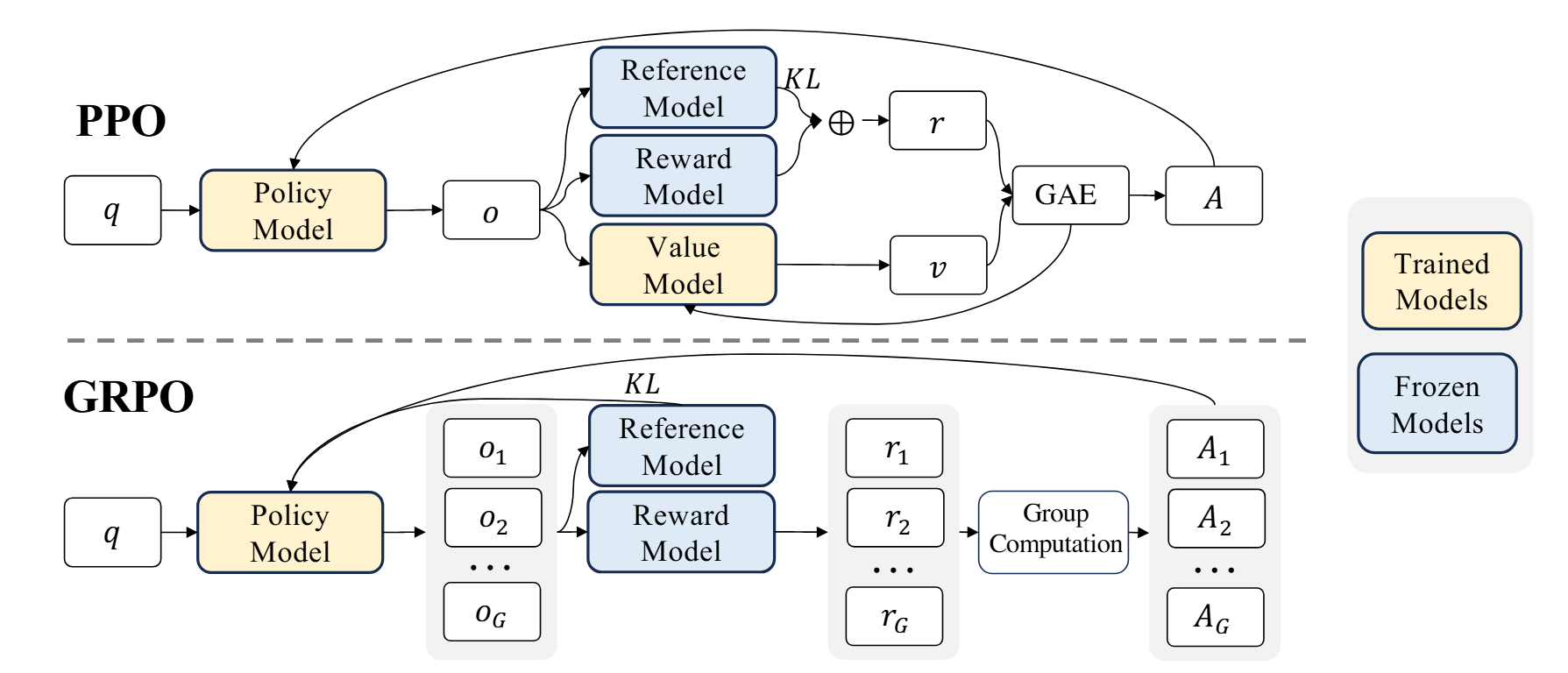 image.png
image.png
如图,PPO 涉及 4 个模型:
- policy model
- reference model
- reward model
- valude model
对于每个sample,
- reward model 分数高:鼓励
- 离 SFT 模型太远:惩罚
1
| final reward = reward_model_score - β * KL(policy || reference)
|
但是 PPO 不是只看 reward,还要看:
text
即:advantage = 实际 reward - value model 预测的 reward
另外还有一个核心的涉及:clip,也就是限制新旧 policy 的变化幅度。
训练流程如下:
1
2
3
4
5
6
7
8
9
10
| Step 1:从一批 prompt 开始
Step 2:policy model 对每个 prompt 生成 response
Step 3:reward model 给 response 打分
Step 4:计算 policy 和 reference model 的 KL penalty
Step 5:得到最终 reward
Step 6:value model 预测每个 token 位置的 value
Step 7:计算 advantage
Step 8:用 PPO clipped objective 更新 policy model
Step 9:同时训练 value model,让它更准确预测 reward
Step 10:重复以上过程
|
DPO
DPO,全称 Direct Preference
Optimization,可以理解成:
不训练 reward model,也不跑
PPO,直接用“偏好数据”把模型调成更喜欢好回答、不喜欢差回答。
完整流程:
text1
2
3
4
5
6
7
8
| Step 1:先拿一个 SFT 模型
Step 2:复制一份作为 reference model,冻结
Step 3:准备偏好数据:(prompt, chosen, rejected)
Step 4:把 prompt + chosen 输入 policy model,算 log probability
Step 5:把 prompt + rejected 输入 policy model,算 log probability
Step 6:同样用 reference model 分别算 chosen 和 rejected 的 log probability
Step 7:代入 DPO loss
Step 8:反向传播,只更新 policy model
|
Loss 的形式:
现在我们拆开 ,得到如下结果:
表示当前模型相比原始 SFT 模型,对 chosen 回答有多偏爱。
另外一项代表当前模型相比原始 SFT 模型,对 rejected 回答有多偏爱。
DPO 希望前者大于后者:chosen 的提升幅度 > rejected 的提升幅度
公式里的 β 是一个超参数,可以理解成:控制模型偏离
reference model 的程度。
伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| for batch in preference_data:
x, y_chosen, y_rejected = batch
policy_chosen_logp = policy.logprob(x, y_chosen)
policy_rejected_logp = policy.logprob(x, y_rejected)
with no_grad:
ref_chosen_logp = ref_model.logprob(x, y_chosen)
ref_rejected_logp = ref_model.logprob(x, y_rejected)
chosen_reward = policy_chosen_logp - ref_chosen_logp
rejected_reward = policy_rejected_logp - ref_rejected_logp
logits = beta * (chosen_reward - rejected_reward)
loss = -log_sigmoid(logits)
loss.backward()
optimizer.step()
|