CogVideoX
Paper:CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
核心问题仍然是视频生成。
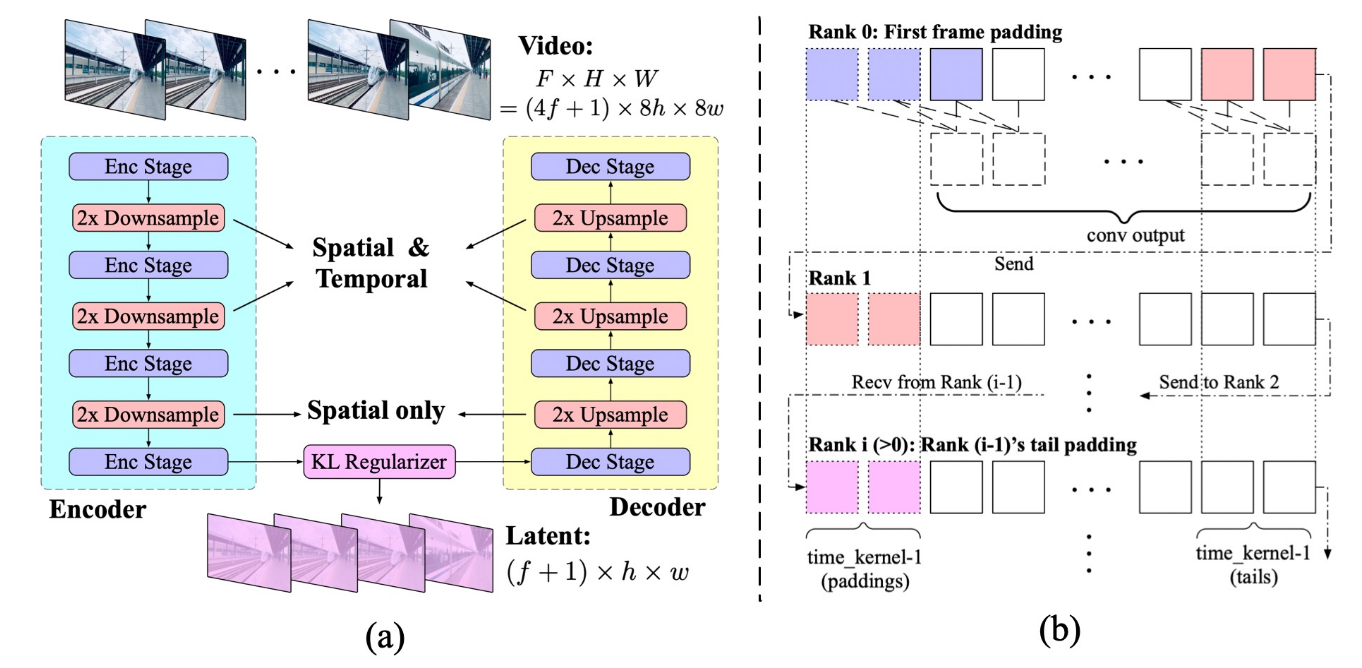
创新点1:仍然是用到了3D 因果自编码器
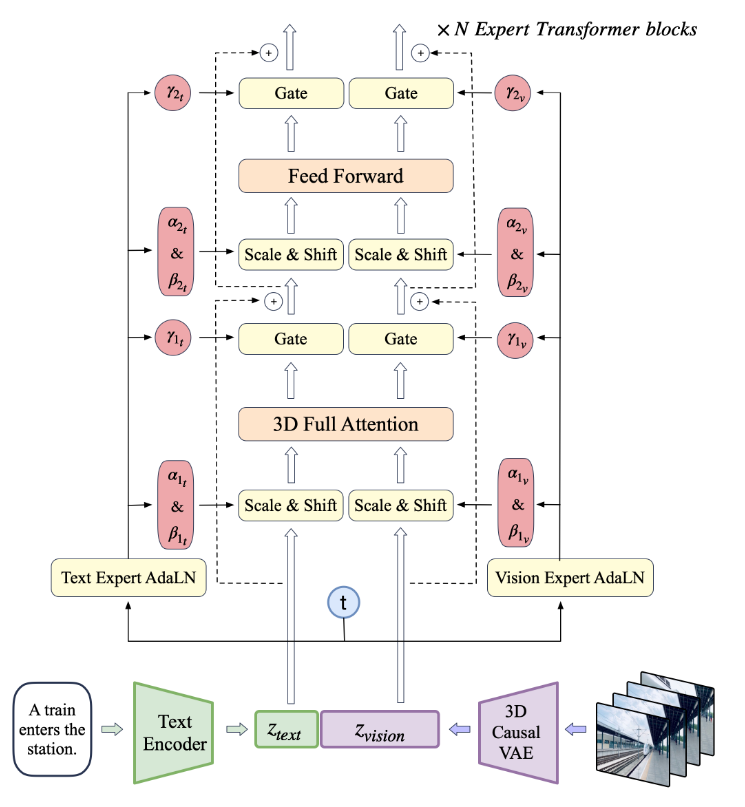
创新点2:专家自适应层归一化
文本特征和视频特征本就属于不同的“世界”(数值尺度和特征空间大相径庭)。如果直接拼接丢进 Transformer,模型会两头不讨好。Sora 等模型为了解决这个问题,往往为文本和视频各自搞一套独立的 Transformer 路径(如 MMDiT),但这会让参数量直接翻倍。
论文的解法非常聪明:保持 Transformer 核心参数共享,但在
LayerNorm
上开辟“文本专家”和“视觉专家”两条独立通道。根据扩散步长
创新点3:3D 全注意力机制与 3D-RoPE
以前的模型为了省显存,喜欢用“2D 空间注意力 + 1D
时间注意力”的解耦设计。但这会导致信息跨帧传递时需要通过背景“间接代传”,一旦物体运动速度过快就会跟丢(产生伪影)。论文直接采用了
3D Full
Attention(全时空注意力),让任何一个画面的局部都能直接看到所有帧的对应位置。同时,将
LLM 里常用的旋转位置编码(RoPE)升级为
3D-RoPE,分别对坐标
创新点4:多分辨率帧打包
为了同时训练长、短、横屏、竖屏的各种视频,传统的做法是裁切或填充。论文借鉴了多模态 LLM 的打包思想,把不同分辨率、不同长度的视频“像拼图一样”打包进同一个 Batch 里,既不浪费数据,又保证了 shape 的整齐。另外,针对数据低质问题,建立了一套利用现成图像模型打标、再让 GPT-4 总结提炼出高质量“稠密视频长描述”的自动化流水线(并蒸馏给 Llama2 加速生成)。
