Mirage
Paper:Latent Spatial Memory for Video World Models
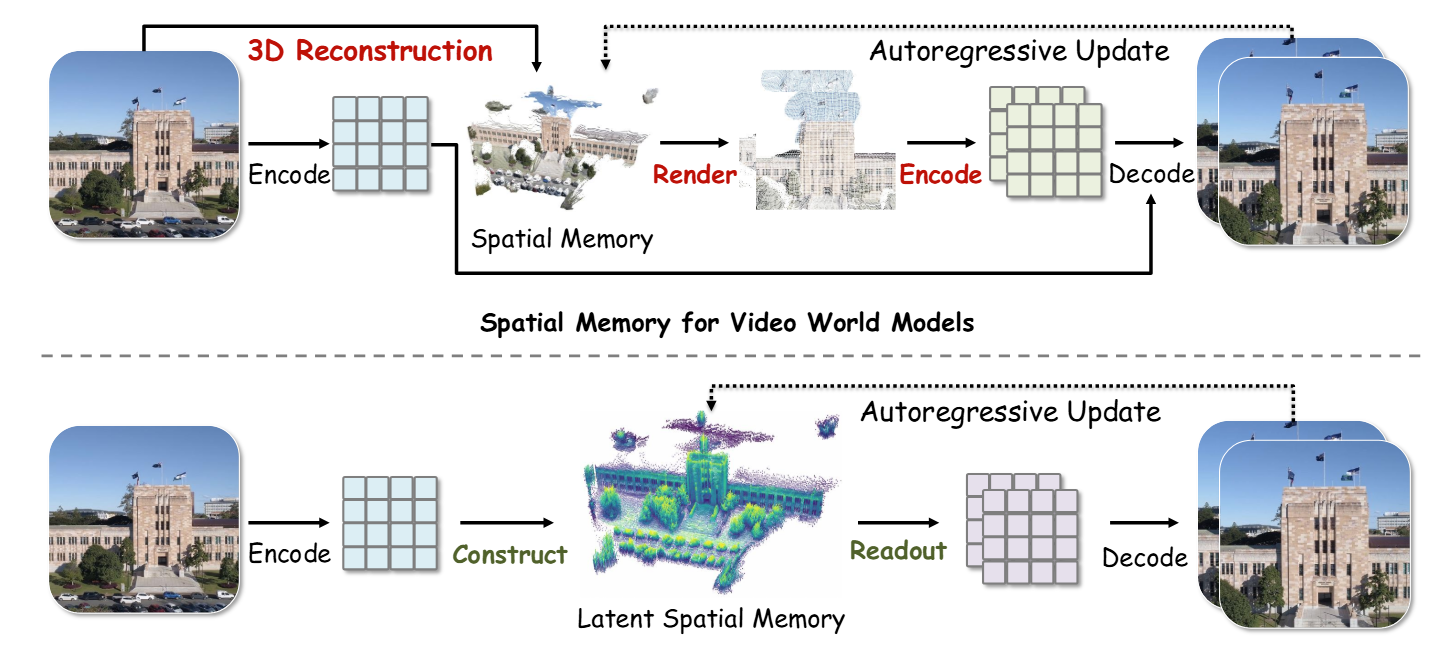
论文解决了什么问题?视频世界模型在生成长序列时,由于缺乏 3D 显式 scaffold 导致的几何漂移问题,同时消除了传统 RGB 3D 点云记忆高昂的渲染与重编码计算开销 。
核心可以学习的点:
- 把 3D 空间记忆直接装进 Diffusion 的 Latent 空间里,而不是像以前那样存在 RGB 像素空间
- 在自回归更新时,利用 Qwen3-VL 提取运动实体标签,SAM 3 提取精准掩膜,联合天空掩膜一起,在写回 3D 记忆时直接切除该部分单元 。
输入:单张初始图像
输出:在空间几何上完全一致、不漂移的未来视频帧序列
其完整流程包含三个阶段:
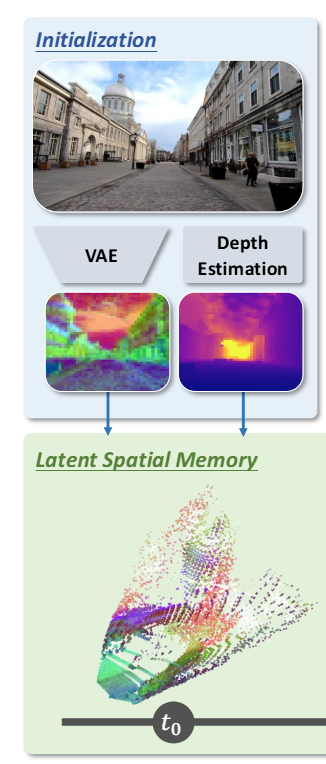
- Memory Initialization (初始化):输入初始帧
,通过 VAE 编码器 得到二维 Latent 阵列 。同时使用单目深度估计模型获取绝对深度 ,并将其下采样至 Latent 分辨率 。通过射线反投影将每个 Latent 单元提升(Lift)到 3D 世界坐标中,构建初始隐式空间记忆 。
- Memory Readout & Denoising
(读取与去噪):给定目标 Chunk 的相机轨迹,将
中的 3D 点云利用 Z-buffer 遮挡剔除技术直接投影到目标视角的二维 Latent 网格上,生成目标视角特征 和一个Mask 。将 和 拼接,输入 ControlNet 侧支注入 DiT 主干。 - Memory Update
(自回归更新):对生成的视频帧解码成像素空间后,用 Reconstructor
重新估计深度与相机参数,同时用 Entity Extractor 和 Video Segmenter
识别并剔除动态物体与天空 。将属于静态场景的新增有效 Latent
特征反投影合并到 3D 缓存
中 。该 Chunk 的 Latent 还会作为短时序 Context 传给下一个 Chunk 。
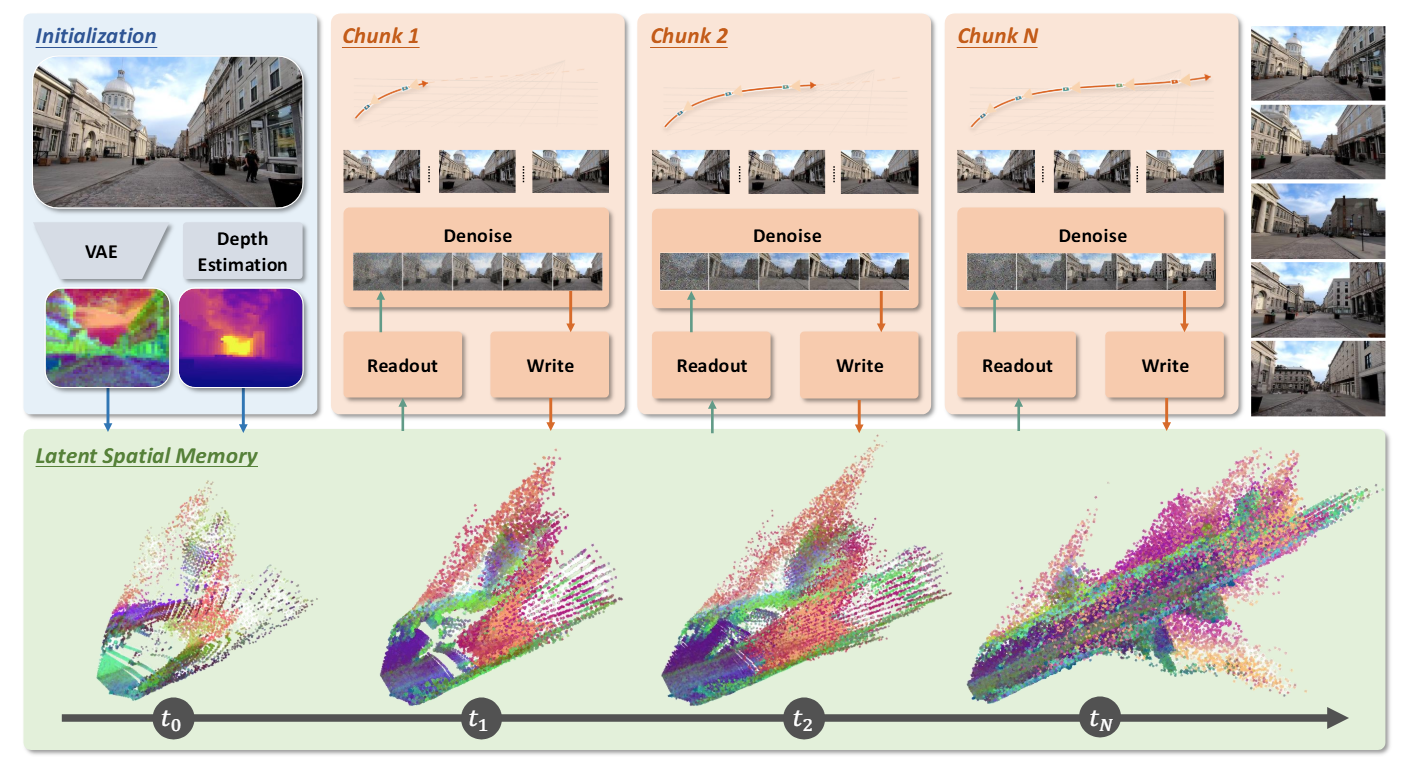
论文采用自回归的方式,每个 Chunk 包含 9 个 Latent 帧(对应 33 帧 RGB) 。
论文用到的模型:
- Depth Anything 3:用于生成度量深度
- Qwen3-VL-2B(实体提取)+ SAM 3(视频分割)用于联合检测出动态前景物体和天空,实现动态物体过滤 。
- VAE:采用冻结的 Wan2.2-TI2V-5B 内置 VAE
如何训练:
- 第一阶段:冻结主干 DiT 和 VAE,只训练 ControlNet
侧支,学习率
。 - 第二阶段:在主干 DiT 的 Self-attention 层接入
rank-64 的 LoRA 适配器,并与 ControlNet
侧支联合优化,学习率
。 - Loss 设计:标准的二维流匹配误差(类似于 Diffusion 的去噪 MSE Loss),直接作用在目标视频帧的二维 Latent 空间上 。
Mirage
https://d4wnnn.github.io/2026/06/11/Notion/Mirage/