RAPID
Paper:RAPID: Reusing Attention Sparsity with Inter-step Adaptation for Efficient Video Diffusion,CVPR 2026
在 DiT 中,现有的稀疏注意力方法存在两个痛点:
- 静态方法:使用预先设定好的固定稀疏模式,虽然计算快,但无法适应复杂的视频内容,导致生成质量下降 。
- 动态方法:为每个 Step 的每个注意力头实时计算 Mask,虽然质量好,但每一步重新计算的开销巨大,抵消了稀疏化带来的加速效果 。
论文提出了一个名为 RAPID 的稀疏注意力框架 。其核心思想非常直白:既然每一步重新计算太贵,那就在生成初期“只计算一次”,然后把这个好用的稀疏掩码缓存起来,供后面所有的步骤复用 。
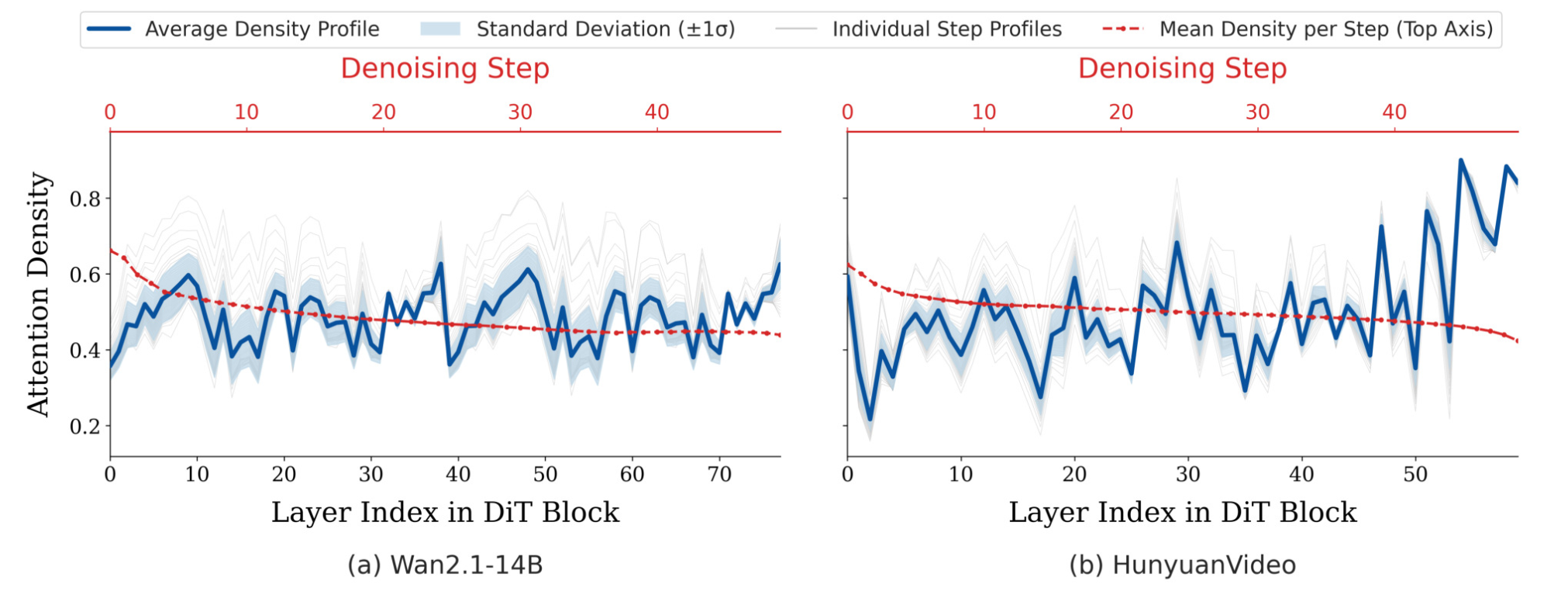
- 看蓝色:随着 Block 索引的变化,所有 step 平均后需要的计算密度。也就是把某一层先全量计算,然后切分成 m 个 Block,经过累加取得得分最高的 n 个方块,计算密度则是 n / m。如图可以看到,DiT 的不同网络层,对内容长程建模的依赖程度不同,对于波峰,必须给足算力,对于波谷,则可以减少计算量。
- 看灰色:分别代表从第 1 步到第 50 步,每一步独立的层级密度曲线 。
- 看红色:代表随着 step 的增加,模型的整体平均计算密度在下降(所有 Block 取平均)。代表早期需要高算力,后期需要低算力。
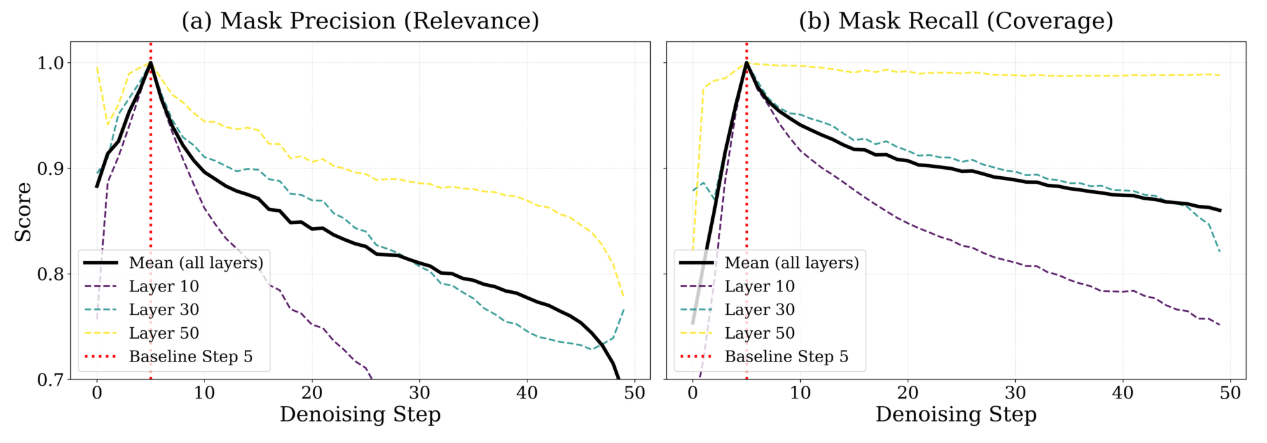
作者在第 5 步时,让模型跑一次完整的 dense
注意力,得到全量的注意力分数矩阵 。然后,利用一种阈值机制,筛选出能保留
95% 总注意力分数的 Blocks 集合
。这些被选中的核心块对应的位置在二进制掩码矩阵中标记为 1,其余标记为
0,这就得到了
对于后续的每一个
step,作者同样用完全相同的方法(保留 95%
分数恢复率),计算出如果在那一步实时计算,最完美的动态掩码
- 左图:Mask Precision:我在第 5 步里决定保留的那些块,到了第
步时,还有多少是真的在发挥作用、没有被浪费的? - 右图:Mask Recall:第
步真正需要的那些重要块,有多少被我第 5 步提前预判到了。
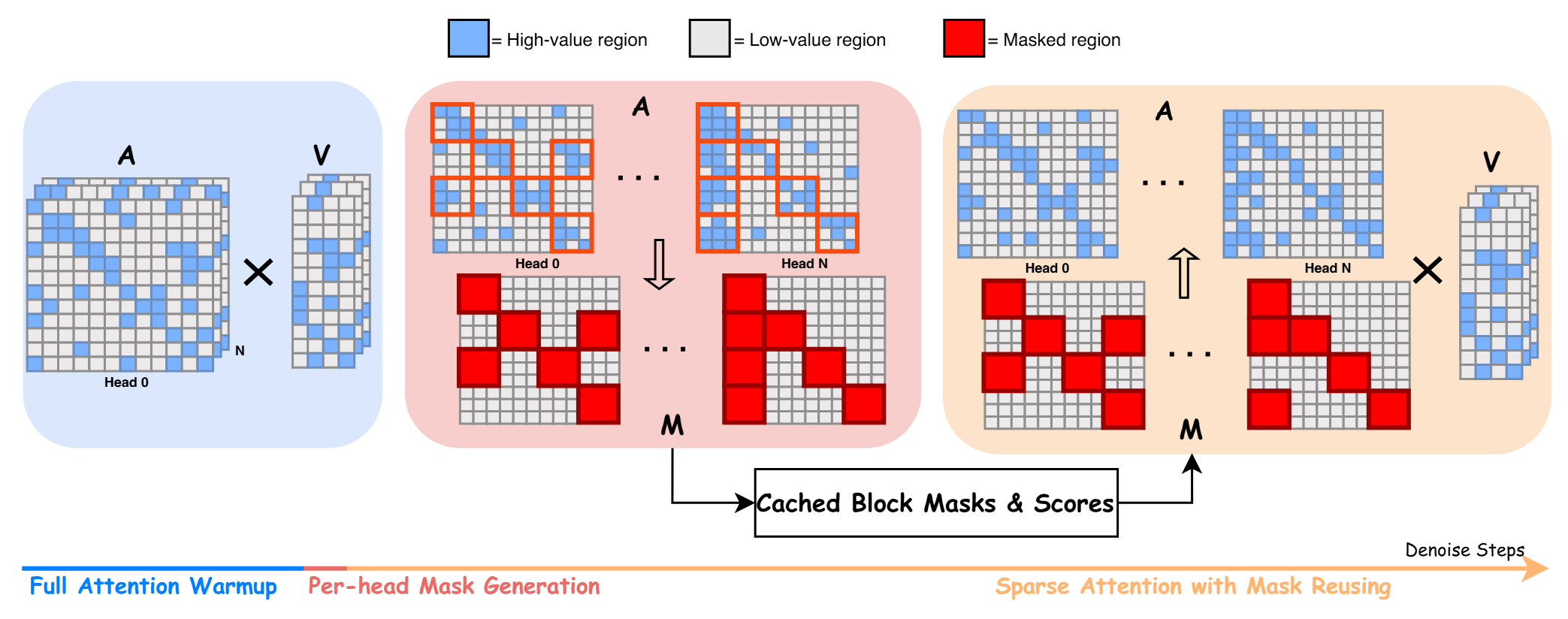
论文并没有在单个 Token 级别打分,而是将整个注意力矩阵划分为
在拿到分数矩阵
- Top-K Anchor(兜底):每行必须先强制选出得分最高的
个键块,确保序列的任何一部分都有基础的连接度 。 - Top-p
Expansion(动态扩展):在兜底的基础上,将剩下的块按分数从大到小排序,累加分数,直到累加值超过该行总分数的某一比例
为止 。
前面提到了“降噪后期模型对稀疏容忍度更高” ,那如何进一步加速?
- 由于我们在初期不仅缓存了掩码
,还缓存了原始的分数矩阵 。当推理进行到中后期(例如某个设定的时间步 )时,RAPID 不需要重新计算注意力,而是直接把缓存里的分数矩阵 拿出来,用更激进(更小)的阈值 重新跑一遍混合选择策略,生成一个更稀疏的掩码 并覆盖缓存 。
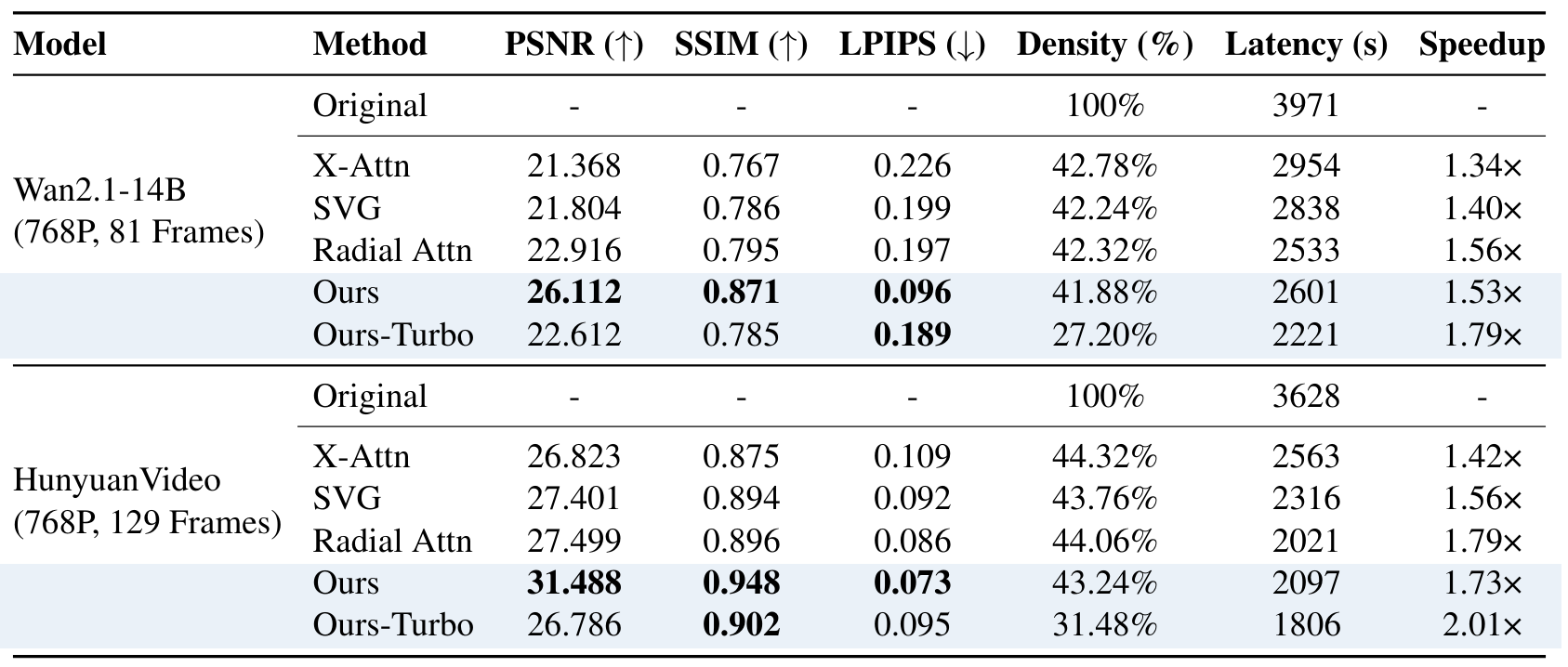
RAPID
https://d4wnnn.github.io/2026/06/12/Notion/RAPID/