HyCa
Paper:Let Features Decide Their Own Solvers: Hybrid Feature Caching for Diffusion Transformers
基于 Transformer 的扩散模型(DiT)在生成图像或视频时,由于需要进行多步迭代推理,计算成本极高、速度慢。
目前行业内流行一种叫特征缓存的免训练加速技术(即通过复用或预测前面步骤的隐藏层特征,来跳过当前步的复杂计算)。但现有的缓存方法有一个致命缺陷:采用“一刀切”(Uniform)的策略,盲目地对所有特征维度应用相同的缓存或预测方式。
论文指出,DiT 的高维特征空间其实非常复杂,不同的特征维度在时间维度上的演化行为是高度异质的(Heterogeneous) :
- 有些维度随时间剧烈波动、频繁震荡 。
- 有些维度则非常平滑、连续且好预测 。
如果用同一种方法去处理它们,要么预测不准导致生成画质暴跌,要么加速效果达不到极限 。
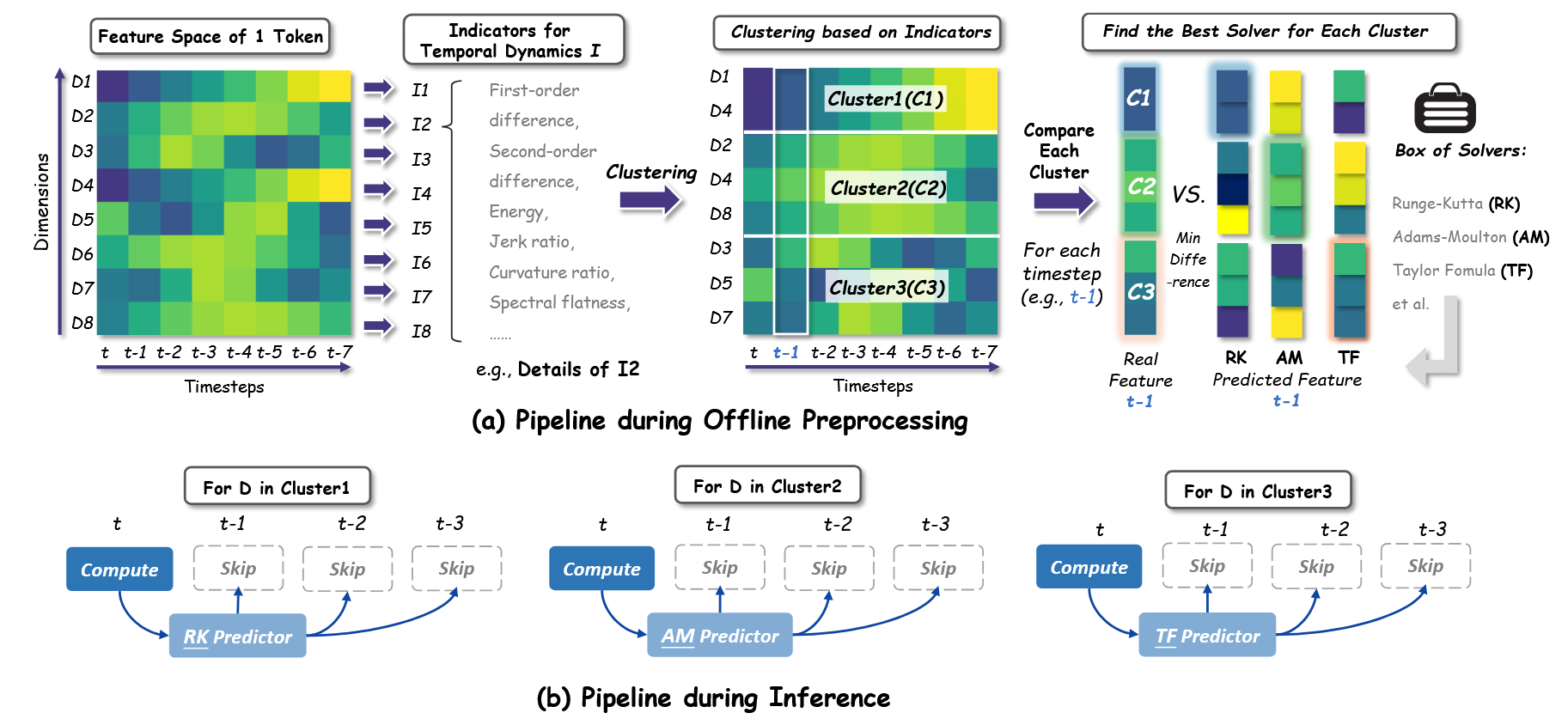
创新点一:维度级动力学聚类
HyCa 不再把整个特征矩阵视为一个整体,而是去分析每一个特征维度(Dimension-wise)的变化规律 。
提取特征指标:
在离线预处理时,让模型跑一步,提取每个维度在时间序列上的动态指标
聚类: 利用 K-Means 算法,将具有相似运动规律的维度聚集到同一个簇(Cluster)中 。也就是说,把“爱震荡的”和“平滑演进的”维度分到不同的班级 。
创新点二:混合 ODE 求解器分配
论文引入了一个求解器池(Solver Pool),里面包含了各种数值分析里的经典微分方程求解器(如 Runge-Kutta, Adams-Moulton, Taylor 预测器等) 。
为了给每个聚类找到最适合的求解器,论文提出了一个核心的优化公式:
对于每一个聚类