DuCa
Paper:Rethinking Token-wise Feature Caching: Accelerating Diffusion Transformers with Dual Feature Caching
传统的基于Token粒度的特征缓存(ToCa)存在两个致命痛点 :
- 计算冗余与效率低下: ToCa 在每一个 Caching step 都坚持去计算所谓的“重要 Token” 。论文发现,在刚开始缓存的第一步,缓存误差其实还没来得及积累,此时去费力计算重要 Token 纯属浪费,导致加速比上不去 。
- 硬件极其不友好: 为了筛选出“重要 Token”,ToCa
需要实时计算复杂的注意力矩阵得分
。这不仅引入了额外的计算开销,更致命的是它不兼容 FlashAttention
等硬件加速算子,导致内存开销从
飙升到 ,实际落地时的推理延迟反而加倍 。
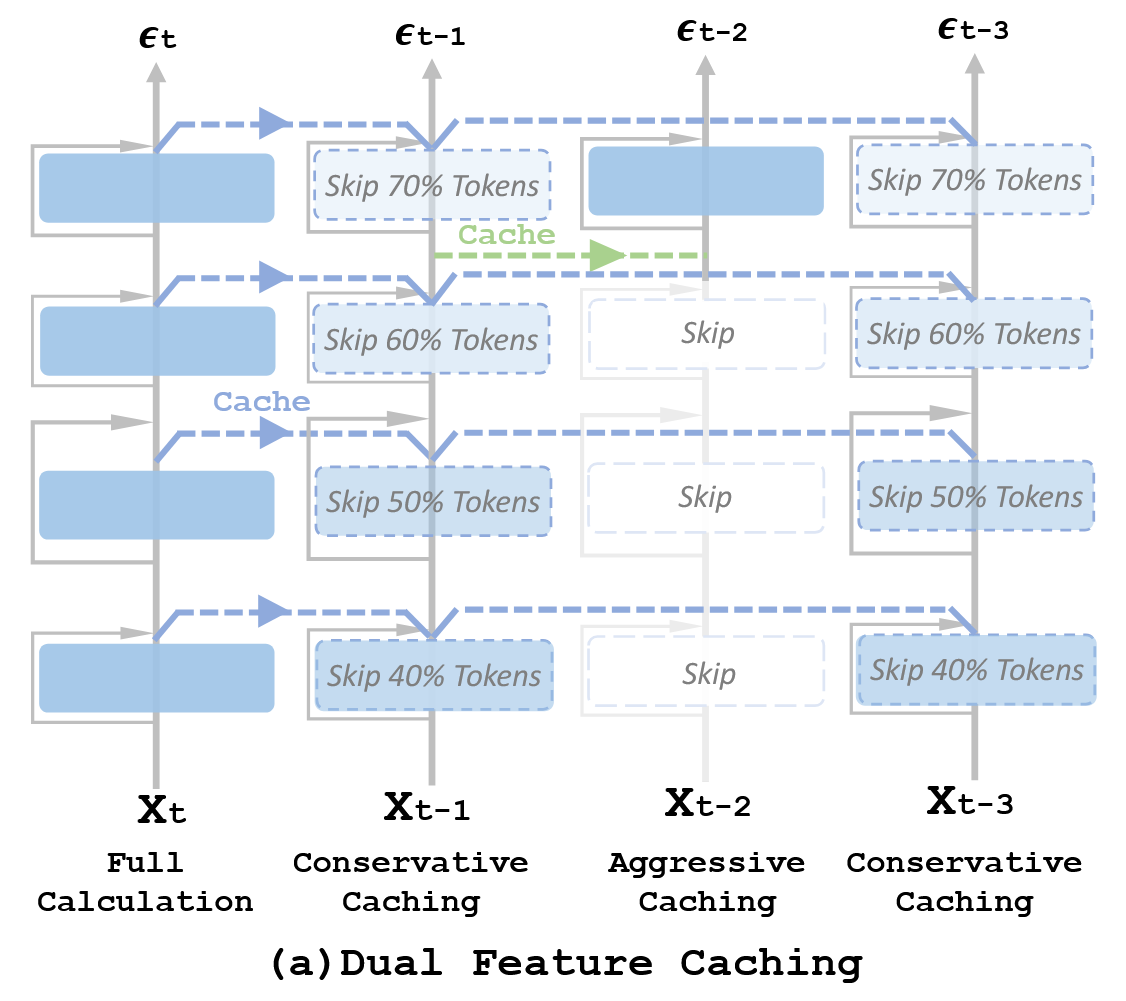
创新点1:动态交替缓存策略
DuCa 不再在每个缓存步都使用同一种策略,而是将激进缓存(Aggressive Caching)和保守缓存(Conservative Caching)交替进行 。
- 激进缓存: 直接用前一步的整层输出替换当前层,几乎跳过整层的所有计算 。
- 保守缓存: 引入 Token 级别的选择性计算,只缓存非残差部分的特征,并对部分 Token 进行真实计算来校准特征 。
创新点2:去中心化的“随机 Token 选择
核心发现: 如果选择彼此相似度极高的 Token 进行重算,效果最差 ;而选择彼此相似度最低(即信息互补、去重)的 Token,效果最好 。
既然多样性最重要,那根本不需要算任何注意力权重,直接用最简单的随机采样来选 Token 就可以完美保证语义的多样性
DuCa
https://d4wnnn.github.io/2026/06/16/Notion/DuCa/