OpenVLA
Paper:OpenVLA: An Open-Source Vision-Language-Action Model
这是一个完全开源的、具备极强通用泛化能力的 7B 参数 VLA 模型。
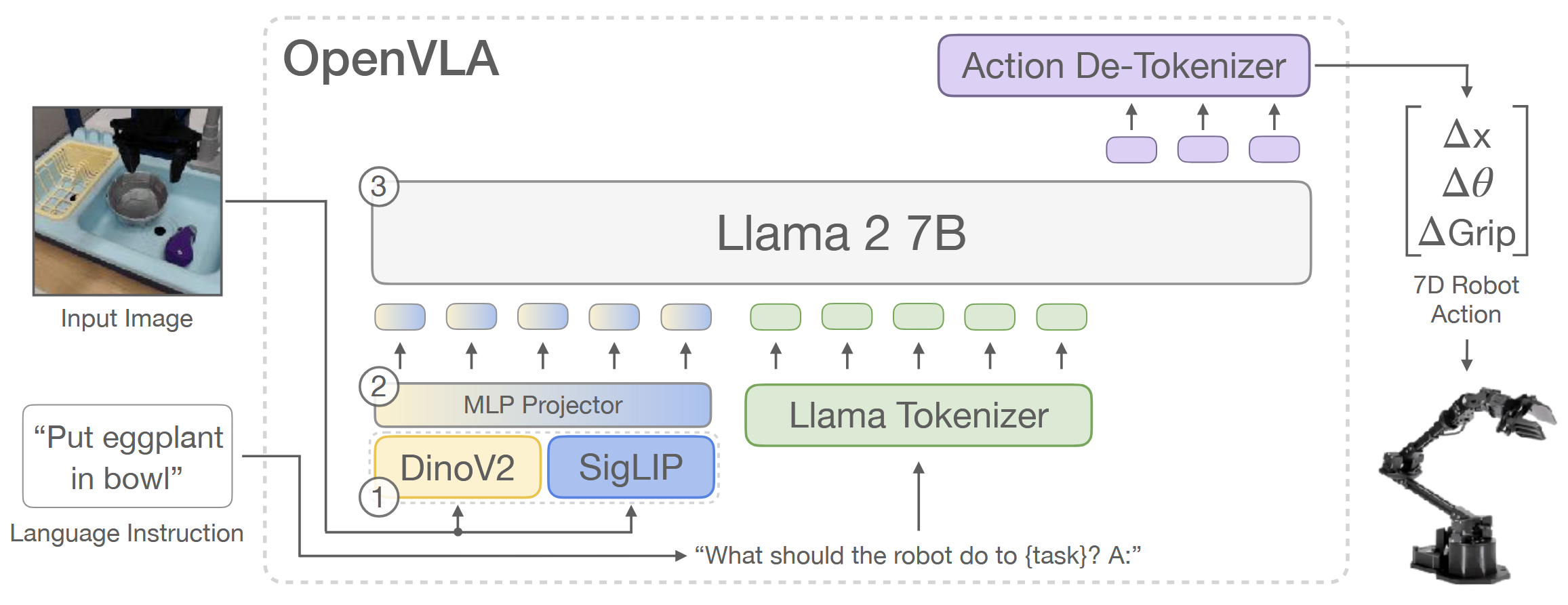
创新的视觉编码器:语义与空间特征的双流融合
- SigLIP:提供宏观的、高层的语义泛化特征 。
- DINOv2:提供微观的、底层的低级空间几何特征(对空间距离、位置更敏感)。
将输入图像同时通过两个网络,并在线性映射层前进行通道拼接,送入 Llama 2 7B 主干 。实验证明这种双流融合能显著提升机器人的多物体空间推理和语言对齐能力 。
连续动作的离散 Token 化
机器人输出的控制动作通常是连续的机械臂位移和夹爪状态,而 LLM 只能输出离散的文本 Token 。论文采用了将动作空间映射到词表的方案 :
OpenVLA 预测的是一个 7 维的动作向量(包括机械臂在三维空间中的平移
另外论文还有一些落地优化:
- 采用 LoRA 微调。
- 4-bit 量化推理
似乎没有什么可以继续看的了……
OpenVLA
https://d4wnnn.github.io/2026/06/17/Notion/OpenVLA/