ImageWAM
Paper:ImageWAM: Do World Action Models Really Need Video Generation, or Just Image Editing?
传统的世界动作模型 WAM 通常依赖视频生成来让机器人“先思考再行动”——即先预测未来的多帧视频,再根据视频推导动作 。但作者指出,这种视频基础的 WAMs 存在三个痛点:
- 计算成本高: 实时生成多帧的高维视频 Token 会带来巨大的计算延迟和推理开销 。
- 容量浪费: 视频生成把大量的模型能力浪费在了与动作无关的背景、光影、甚至相机运动等时间与外观细节上 。
- 复合误差(幻觉): 视频生成的任务太难了,一旦生成的视频中物体发生扭曲(幻觉),就会直接误导下游的动作预测器导致任务失败 。
那么论文是怎么解决的呢?
- 传统的视频 WAM 预测的是一整个序列,而 ImageWAM 只预测终点帧。
- 真推理,假生成。不需要 Decode 图像。
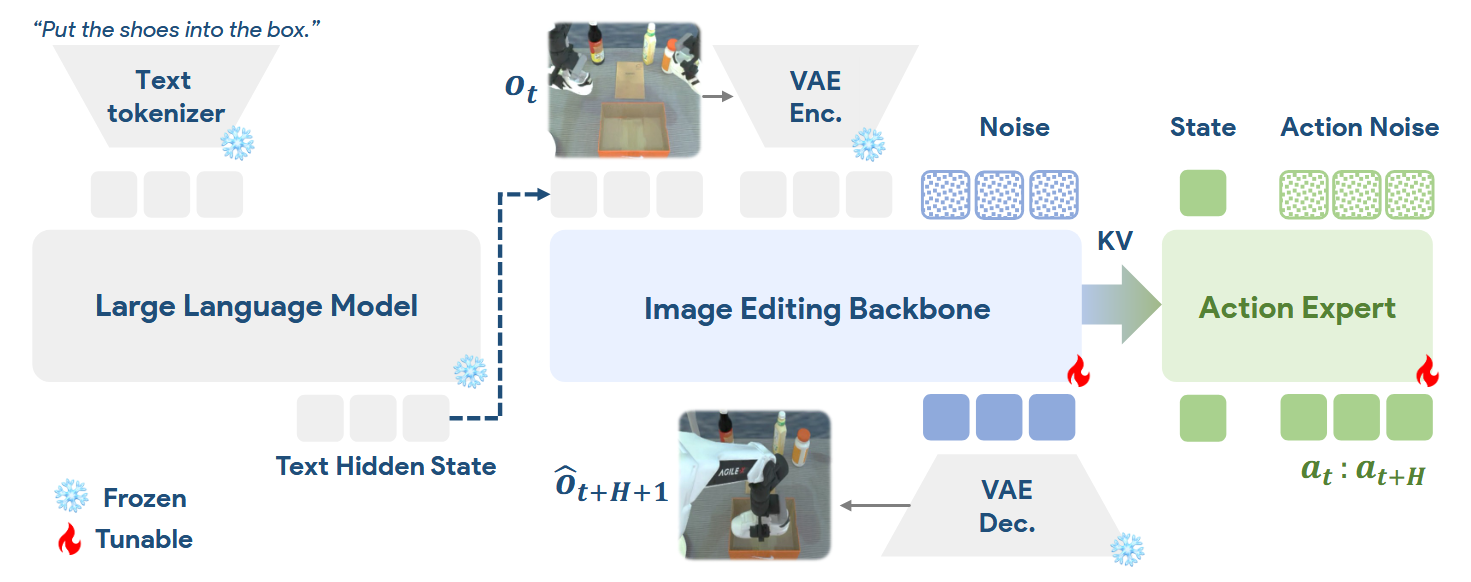
意思是说,一共 N 层 Layer,每层有两部分:
- Image Editing Backbone(Freeze)
- Text Token
- Image Token
- Noise Target Image Token
- Action Expert
- State Token
- Noise Target Action Token
然后将这两部分的 Token 拼接,做一次 Self Attention,然后拆开,各自做 FFN。
然后
- 对于 Text、Image、Stage,只能互相看,看不到加噪的 Token。
- Noise Target Image:看不到 Target Action。
- Noise Target Action:看到所有
ImageWAM
https://d4wnnn.github.io/2026/06/19/Notion/ImageWAM/