DuCo
Paper:DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
针对 DiT 的一个加速方案,但不是 Training-free.
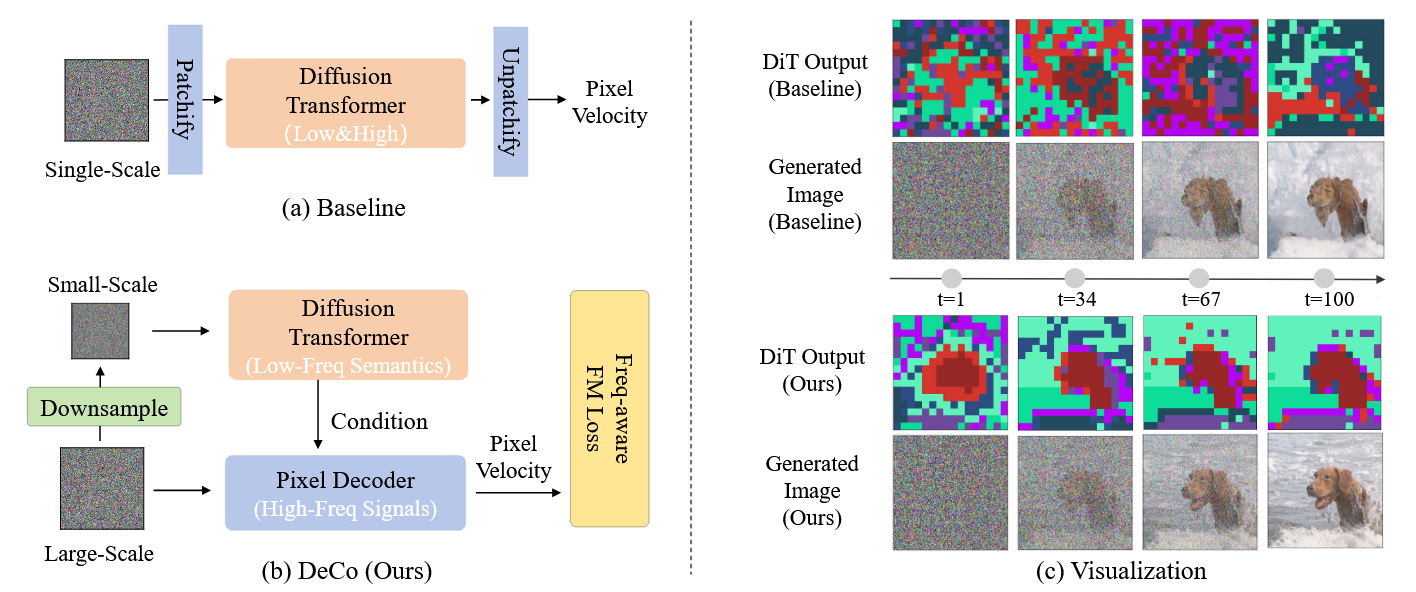
论文在架构上进行了解耦,将 DiT 拆分成两部分:
- 低频语义分支:将输入图像先进行下采样降低分辨率,丢弃大部分高频噪声 。然后让主体的 DiT 只在低分辨率输入上专门学习低频语义。
- 高频细节分支:引入一个非常轻量、不含自注意力机制的 Pixel Decoder 。它直接接收全分辨率的噪点图像作为 Dense Query(密集查询),在 DiT 输出的语义特征指导下,快速缝合还原出图像的高频细节 。
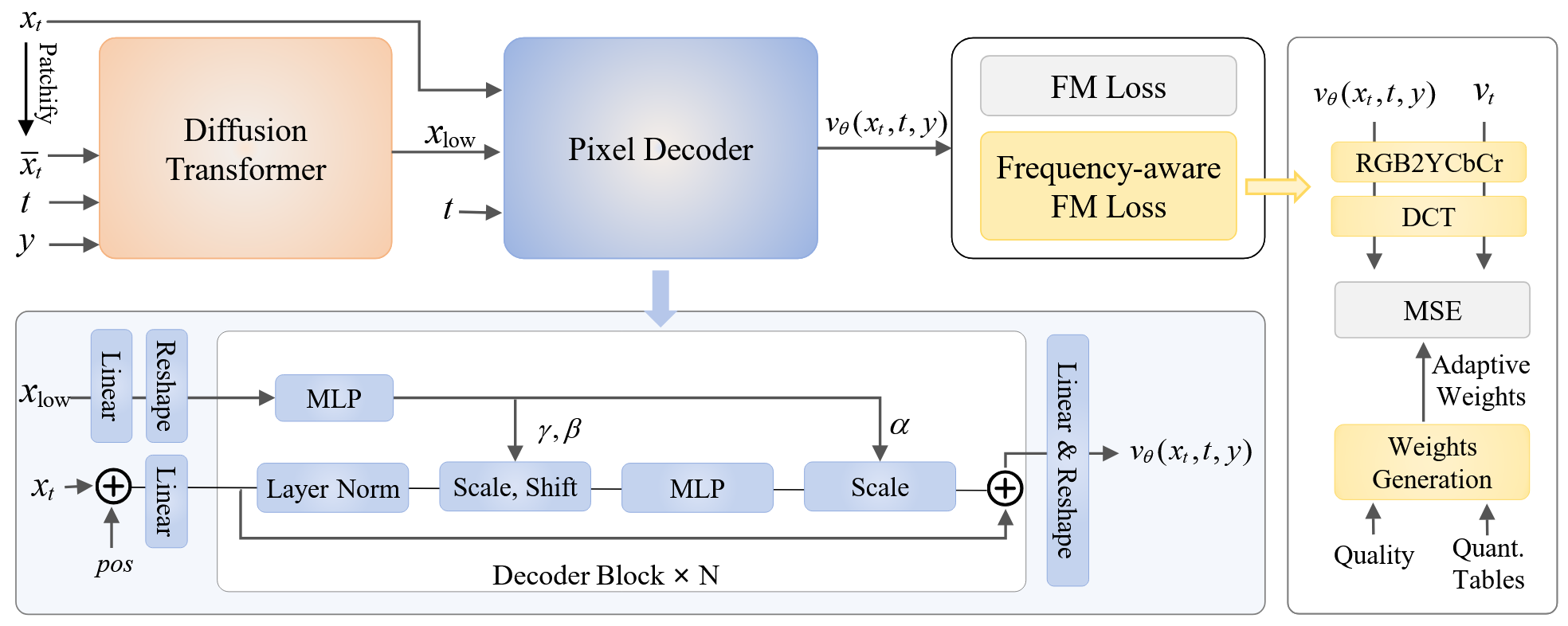
首先是 Diffusion Transformer:
- 输入:Noisy Token
- 条件
- 时间步 t:正余弦编码 + MLP
- 类别 y:查表得到embedding,与 t 相加 + SiLU
- 文本 y:Qwen 编码后,通过 cross-attention 注入
- 然后输出
然后是 Pixel Decoder:
- 对每个 Patch,需要找到对应的语义 Token 经过 AdaLN 调制,然后 MLP 输出。
Loss 有哪些?
:主扩散损失,像素空间 :频率自适应流匹配损失 和 是频域速度矩阵 。 :把 DiT 网络的中间层特征,去和预训练好的视觉大模型(如 DINOv2)提取出的特征进行强行对齐
DuCo
https://d4wnnn.github.io/2026/06/20/Notion/DuCo/