基于扩散的VLA路线:Diffusion Policy、\pi0 与 \pi0.5
Diffusion Policy
Paper:Diffusion Policy: Visuomotor Policy Learning via Action Diffusion,2024
论文算是 VLA 在 DIffusion Policy 路线的开拓者之一。
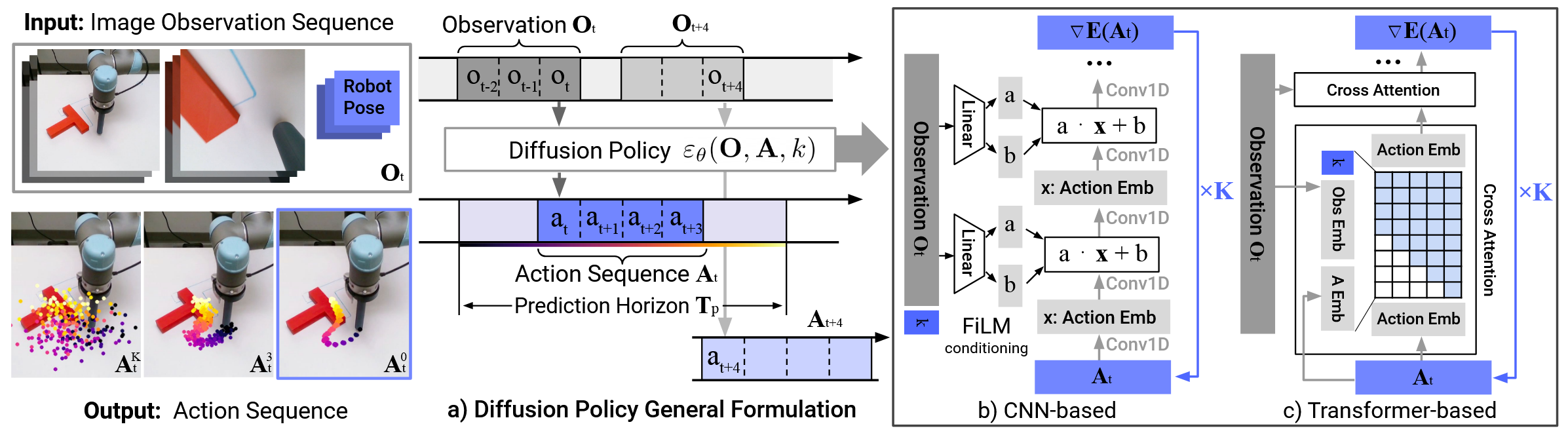
将 Image 经过 CNN 等抽取特征后,进入 Diffusion 与 Noise Token 拼接(或者 FiLM 调制)并去噪。
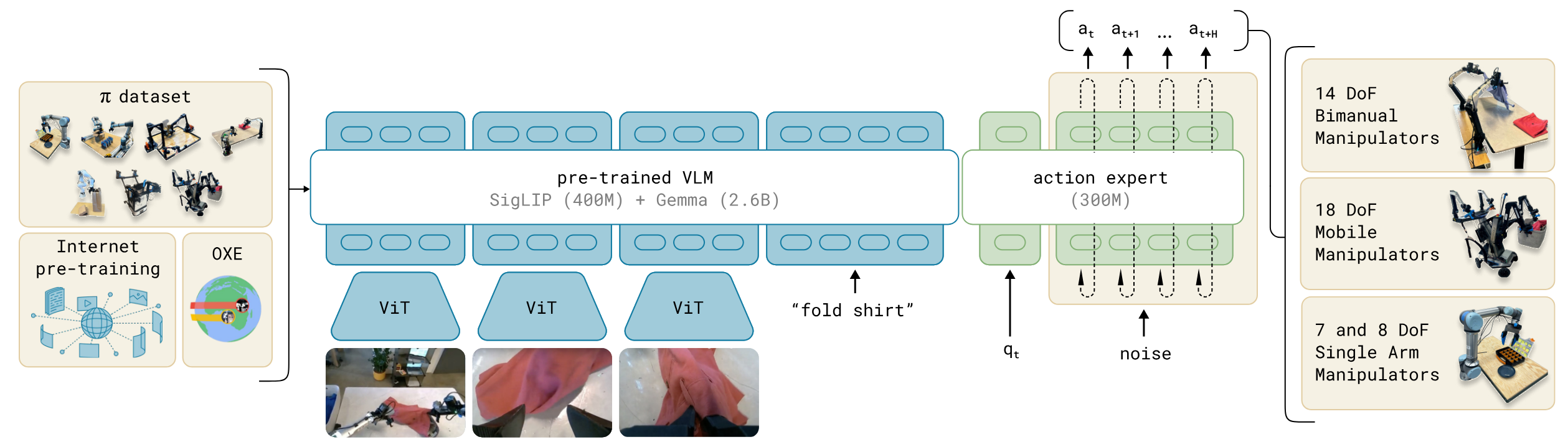
Paper:π0: A Vision-Language-Action Flow Model for General Robot Control,2024
这是一个基于扩散的路线,分成两部分:
- VLM 侧:
- Image、Text Token
- Diffusion 侧:
- 处理后的 Image、Text Token (只能看到彼此)
- State Token (只可以看到Image、Text和自身)
- Noise Action Token (可以看到所有)
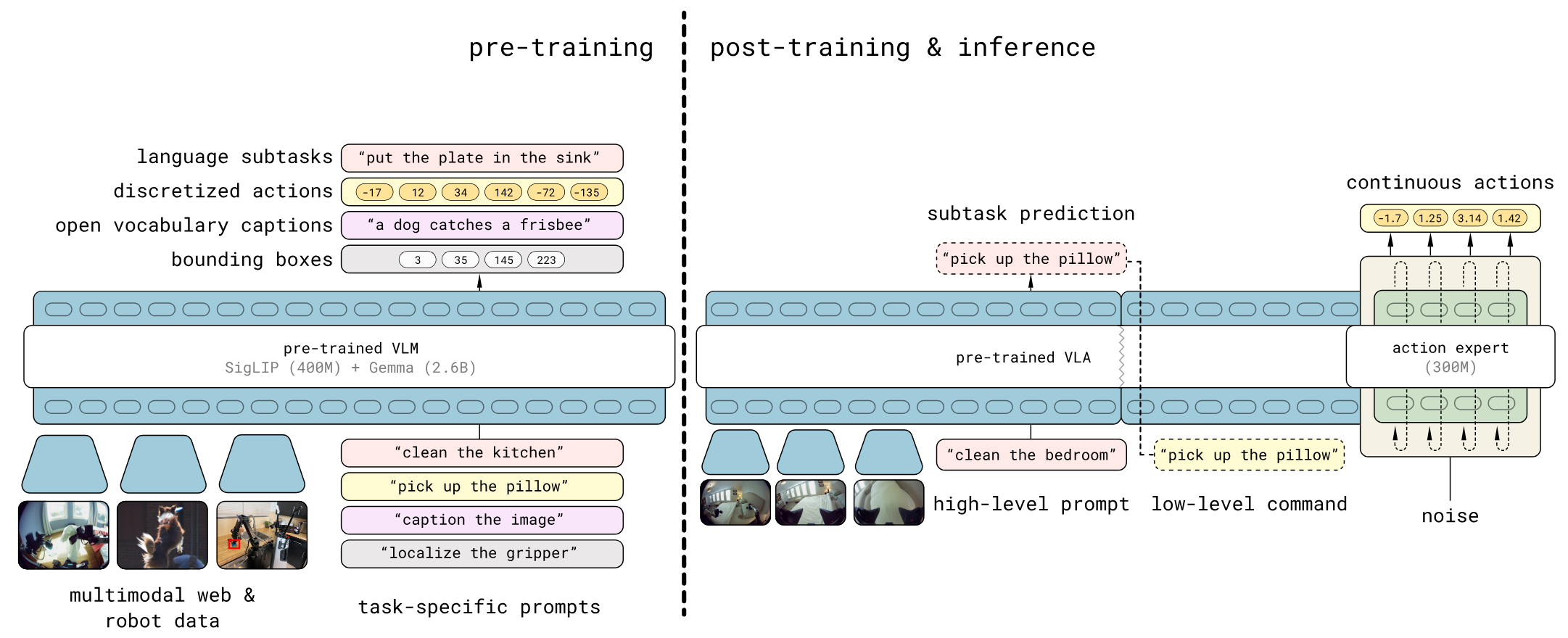
Paper:π0.5: a Vision-Language-Action Model with Open-World Generalization,2025
也是一个基于扩散的路线。
与 "pick up the pillow")
,然后再把这个新吐出来的文本作为上下文,喂给低层的动作专家去生成动作
。
基于扩散的VLA路线:Diffusion Policy、\pi0 与 \pi0.5
https://d4wnnn.github.io/2026/06/21/Notion/基于扩散的VLA路线:Diffusion Policy、!pi0 与 !pi0.5/