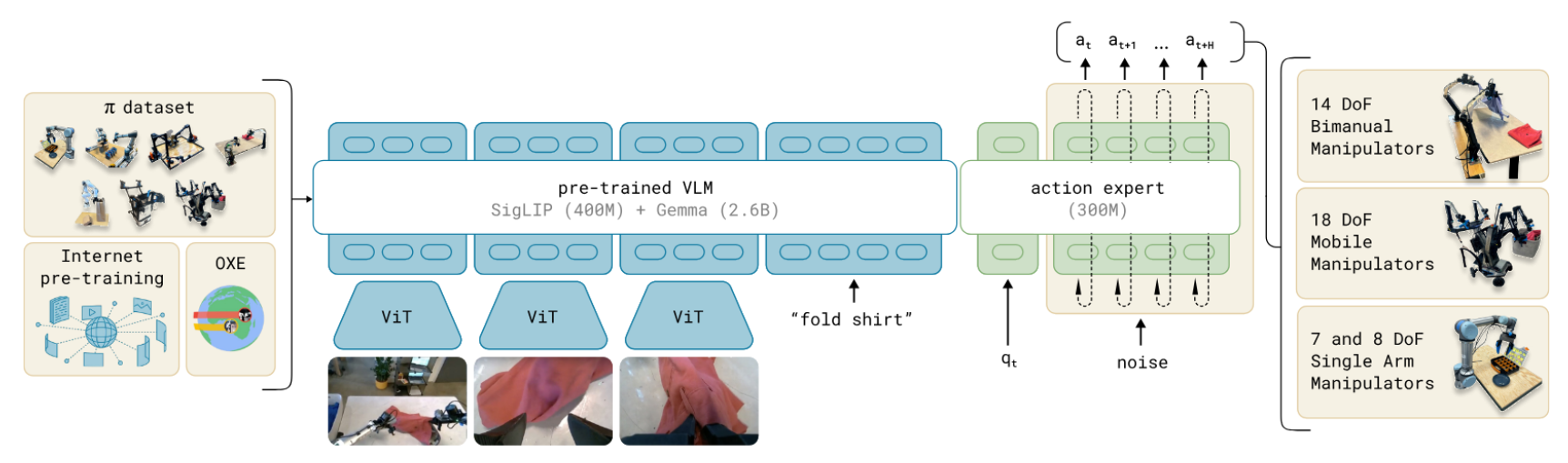
VLA & World Model
World Model 可以分成哪些?
如果是按照状态表示划分的话,我觉得可以分成三种:
- pixel or video:比如 Sora,Kling,WoW,Cosmos
- 3D 显式表达:比如 3D-VLA
- latent token:比如 Genie 1/2/3
如果是按照生成方式的话,我也觉得可以分成三种:
- 自回归的
- Diffusion or Flow Matching
- 混合的
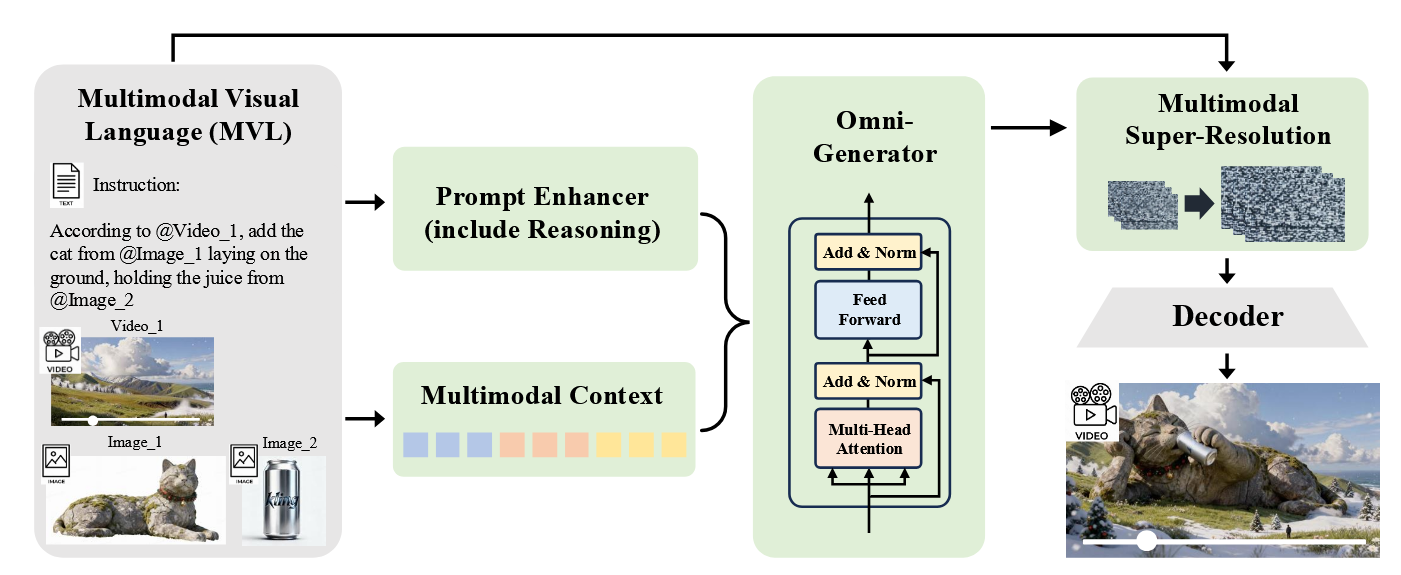
Kling-Omni
输入:文本、图片、视频
输出:视频
接收多模态输入,然后 LLM 进行 Prompt 增强,Diffusion Transformer 接收增强特征和原始多模态 Token,在共享的 Embedding 空间内进行跨模态交互,生成视频。
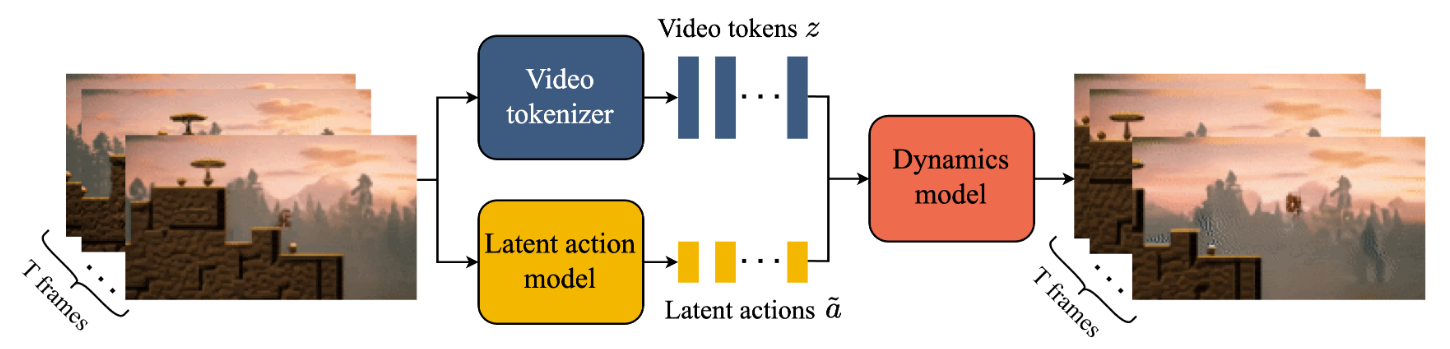
Genie
DeepMind 提出,技术路线是自回归,世界状态是 latent token。
输入:图像 + 离散动作
输出:下一帧
模型的技术路线是自回归的。首先训练一个 Video
Tokenizer(基于VQ-VAE)。然后第二阶段冻结 Tokenizer,潜在动作模型LAM
提取动作(观察前后两帧),然后输出动作。然后一个 Decoder 接收历史的
video tokens
WoW
技术路线是 Diffusion,世界状态是 pixel。
输入:图像 + Prompt
输出:未来帧 + Action(机器人的 7 自由度动作序列,7-DoF)
这个一般用在 VLA 领域,首先输入一个图像,然后生成未来预测帧。引入 VLM 来审查这段视频,给出 Reward,让大模型去修改 Prompt,直到画面符合物理逻辑。最后根据预测视频帧提取动作序列(FM-IDM)。
另外,FM-IDM这个逆动力学模块是单独训练的,用 SAM 处理当前帧得到机械臂的 Mask,然后用 CoTracker3 提取两帧之间的光流,捕获精细的动作动态。然后将上述特征拼接一个 DINO,送入 MLP 预测 7自由度的动作特征。
什么是光流?
视频相邻帧之间,像素级别的运动偏移量,本质上是一个记录了每个像素运动方向和距离的 2D 向量场。
VLA 的范式一般是什么?是论文这样吗?
一般的 VLA 是输入图像+Prompt,直接输出动作序列。但是这里是先生成未来帧,再通过逆动力学生成动作序列。
🎉目前最主流的 VLA 是自回归的(OpenVLA),先把机械臂动作离散化,变成 Token,然后根据前面的图像和文本,自回归的生成动作序列。
- 优点:完美复用 LLM 的框架和基座,常识推理极强。
- 缺点:机械臂的动作是连续的,离散成 Token 会丢失精度,不够平滑,且容易累积误差。
🎉另一条范式是基于 Diffusion 架构(比如 Diffusion Policy)。
- 优点:动作很丝滑。能处理多峰分布,比如桌子中间一个水杯,机器人可以从左边也可以从右边过去,自回归容易把轨迹平均,直接撞上水杯,而 Diffusion 能完美塌陷到其中一条正确的路径上。
- 缺点:推理很慢。
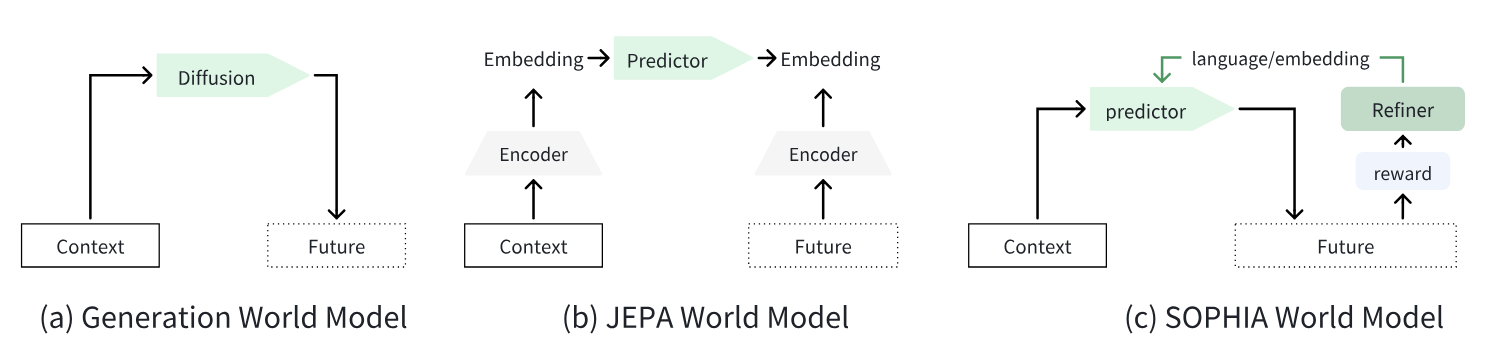
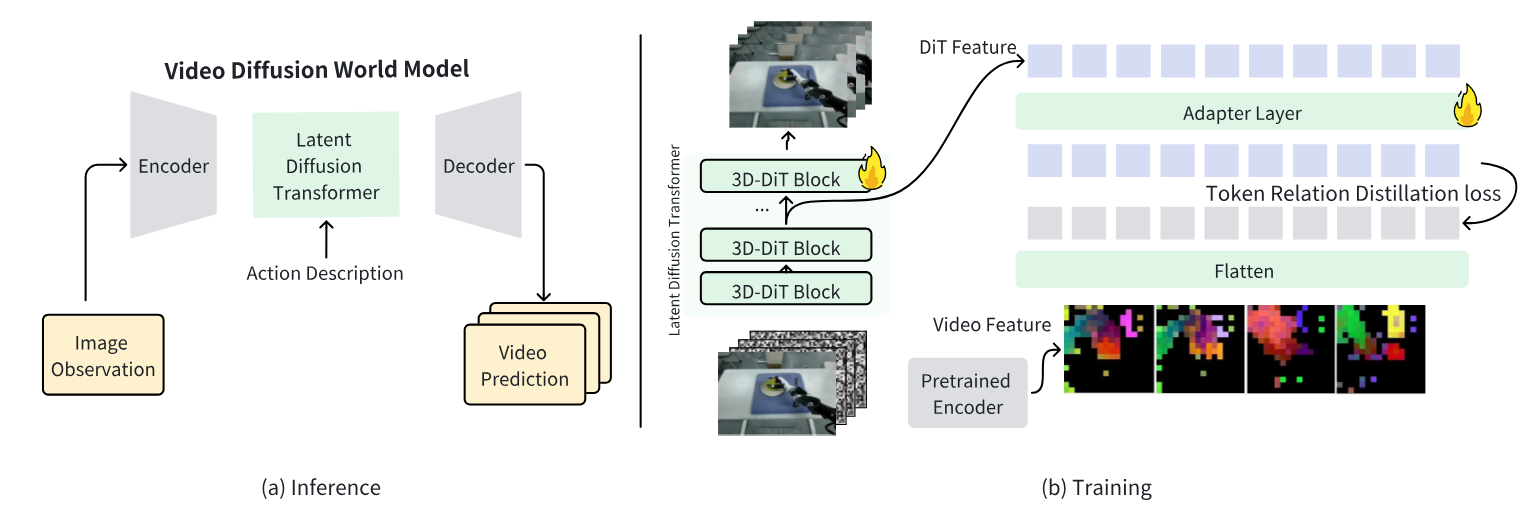
JEPA
Paper:Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
技术路线不是自回归也不是 Diffusion,更像是一个基础模型。
从一个图像块随机挖掉几个比较大的区块作为目标,把剩下部分作为上下文,喂给编码器。然后把这个 latent feature 和目标的位置信息给一个 predictor,得到目标的 latent feature,计算 l2损失。
既然不使用对比学习的负样本,I-JEPA 是如何避免特征坍缩的?
- I-JEPA 采用了非对称架构来避免坍缩 。具体来说,它的目标 Encoder 不是通过梯度下降优化的,而是由上下文编码器 Encoder 的指数移动平均(EMA)来更新 。
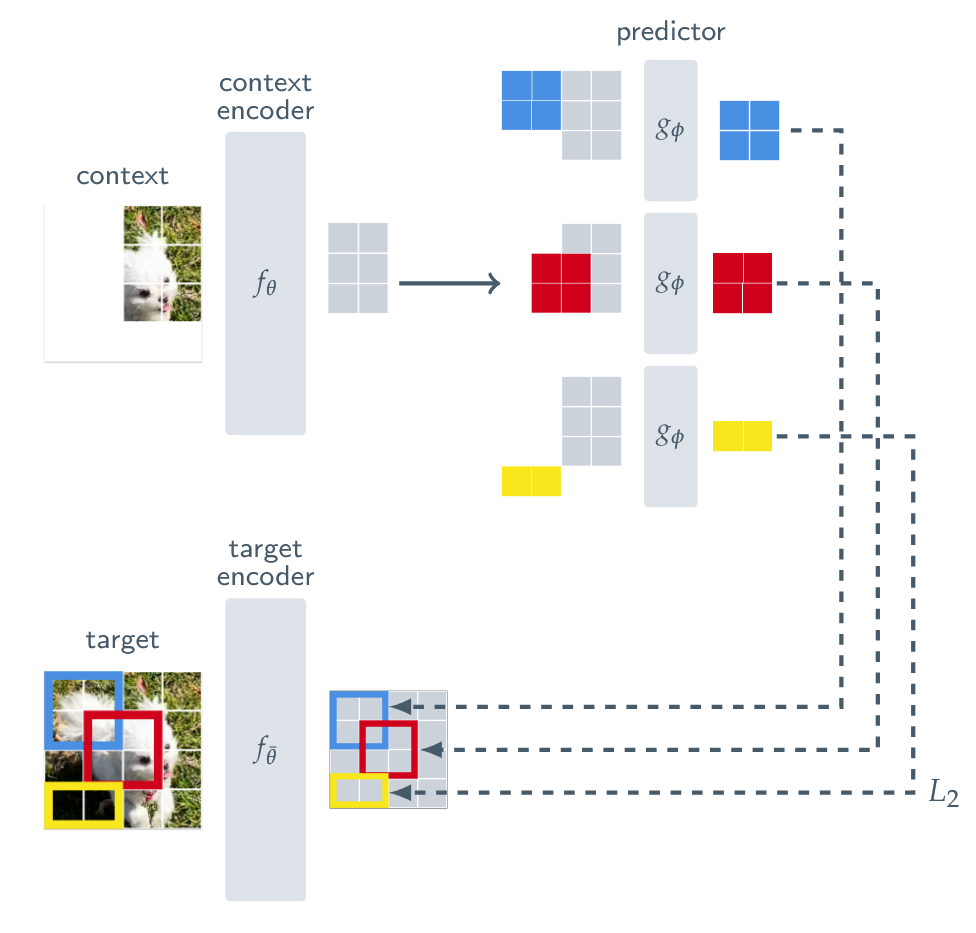
V-JEPA
Paper:Revisiting Feature Prediction for Learning Visual Representations from Video
类似 I-JEAP。仍然缺乏交互和动作条件。
V-JEPA 和 VideoMAE 的本质区别是什么?
- VideoMAE是像素级重建,会浪费算力在高频细节,而V-JEPA是潜空间预测。
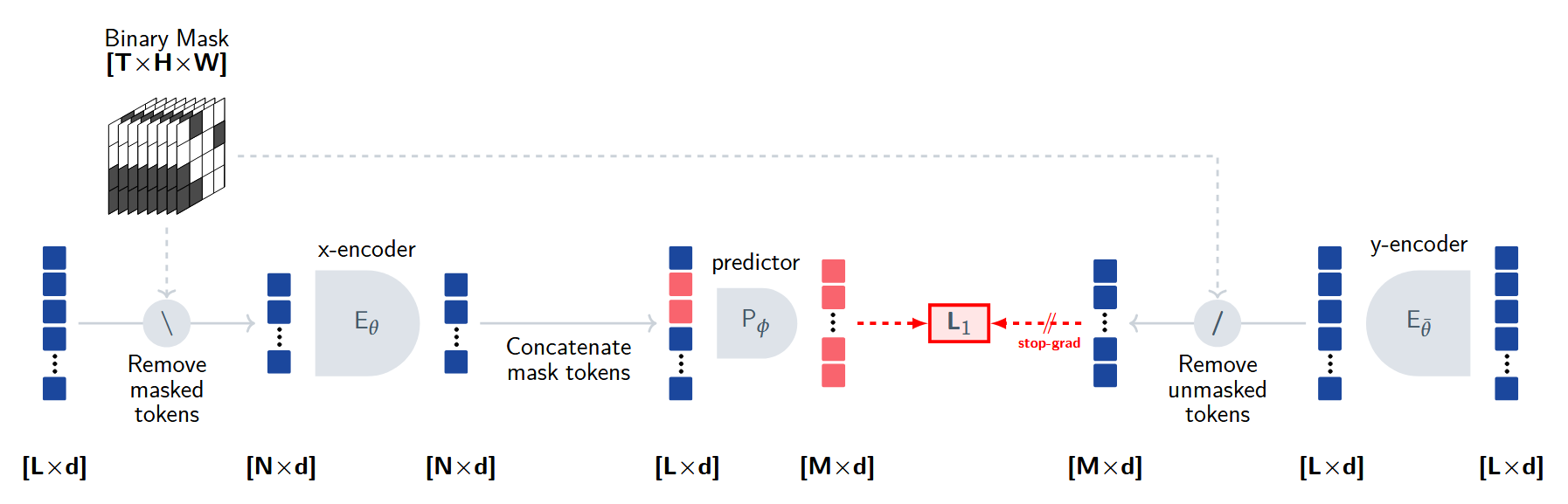
V-JEPA 2
paper:V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
首先在预训练阶段:
- 参考 V-JEPA,得到视频的编码器。
然后在后训练阶段:
- 冻结编码器,引入机器人的状态,预测未来帧的 latent token。

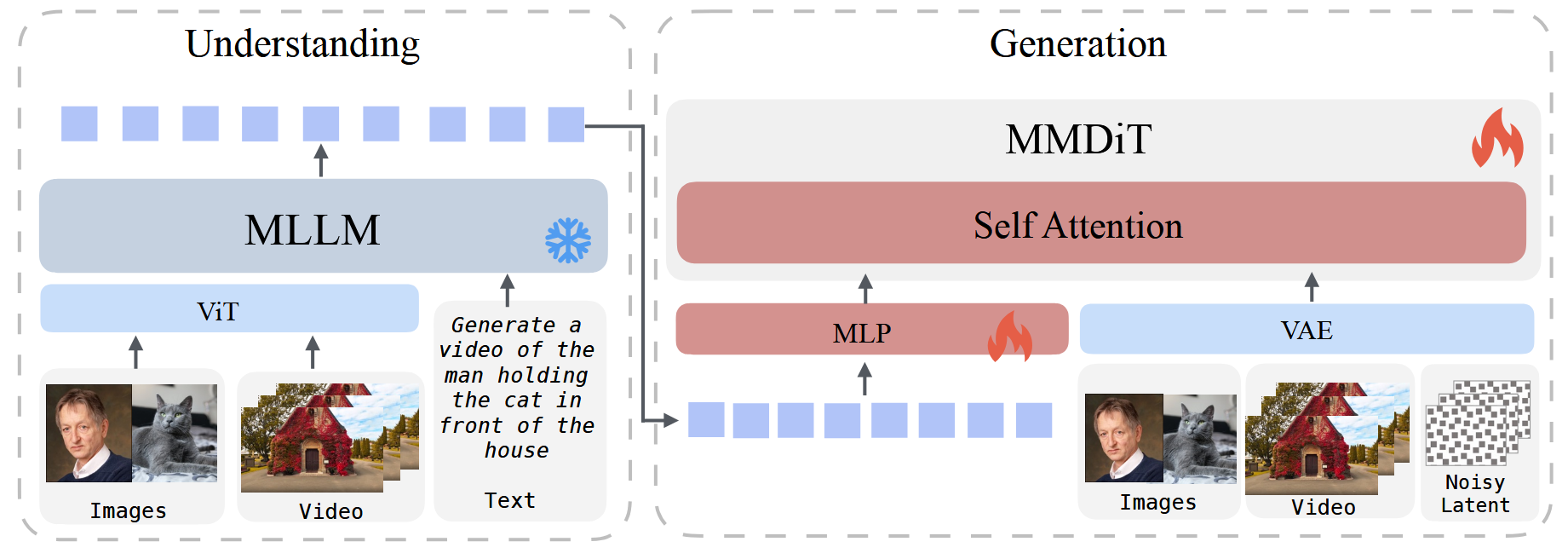
UniVideo
可灵团队。
将多模态 LLM 和 多模态 DiT 结合起来。
也就是首先完全冻结 DiT 和 MLLM,只训练 MLP。
然后依然冻结 MLLM,联合训练 MLP 和 DiT。然后多任务训练。
MovieGen
如何过滤清洗数据?

- Visual Filtering:
- 分辨率限制:去掉宽或高小于 720 px 的低清视频。
- 长宽比平衡:保持 60%的横屏数据和40%的竖屏数据。
- 文字移除:利用视频OCR移除掉包含过多水印,外挂字幕或者嵌入文本的视频。
- 镜头转场切分:原始视频在4s~2min不等,使用 FFmpeg 进行场景边界检测,找出其中大于16s的连续单镜头,随机截取一段4s~16s的视频片段。
- 美学打分:剔除掉严重压缩或者模糊的视频。
- 黑边检测:去掉有黑边的是屁。
- Motion Filtering:
- 去掉纯静态的或者超慢动作。
- 去掉抖动的。
- 去掉纯后期特效的视频。
- Content Filtering:
- 去重。
- 对视频聚类并重采样。
- Captioning:
- 使用微调过的 LLaMa3-Video 为每个视频生成 Caption(100 words左右)。
- 额外训练了一个镜头运动分类器,能够自动识别出 zoom-in(放大)、pan-left(左摇)、tracking shot(跟镜头)等 16 种电影运镜级别。识别出高置信度的运镜后,会将该词作为前缀(Prefix)强制拼接到 LLaMa3 生成的 Caption 最前面。
最终保留了大约 100M 的视频文本对。
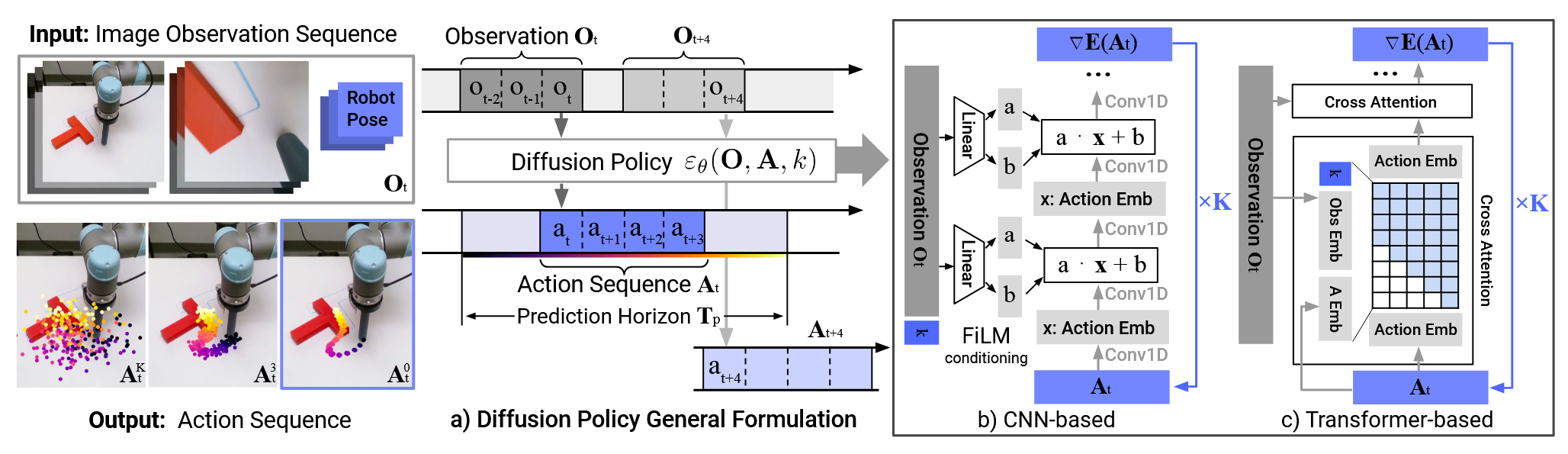
Diffusion Poilcy
Paper:Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
这篇论文提出了一种新的机器人学习方法,将机器人的视觉运动策略建模为一个基于条件降噪的扩散过程,从而生成稳定且高质量的动作序列 。
传统方法有什么问题?
- 以前的显式策略会把左右两种动作平均,导致机器人直接撞向障碍物 。
- 基于能量的隐式策略虽然能拟合多模态,但训练极不稳定(需要负采样)。
Cosmos
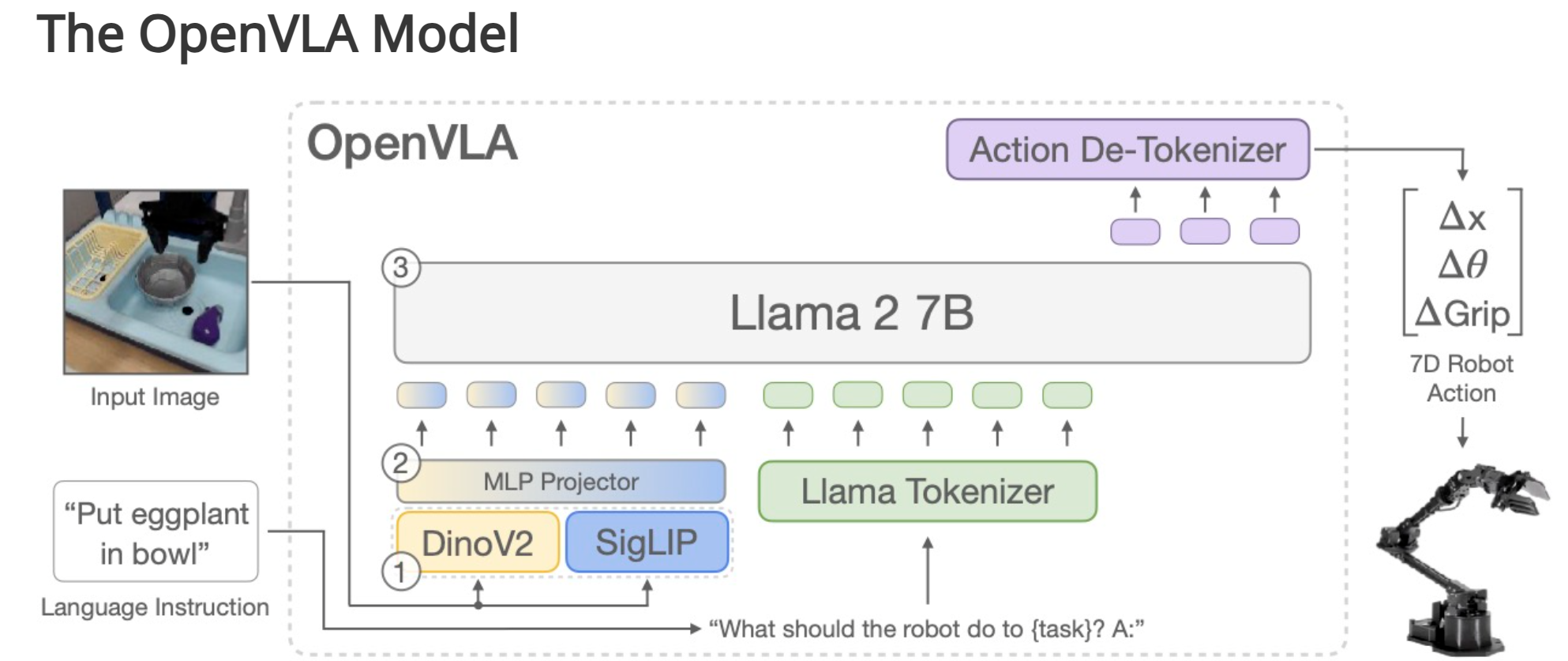
OpenVLA
自回归路线,自回归的输出 Action 序列。
主要路线是基于扩散模型的。只不过这里的条件控制是需要经过大模型,然后大模型的 Token 和 机器人的状态 Token 和 noise latent 拼接在一起。然后块内采用全自注意力,块间采用因果注意力。